- Rising through the Ranks
Multi-scenario search result ranking is better at finding users what they want, however they’re looking for it
This article is part of the Academic Alibaba series and is taken from the paper entitled “Learning to Collaborate: Multi-Scenario Ranking via Multi-Agent Reinforcement Learning” by Jun Feng, Heng Li, Minlie Huang, Shichen Liu, Wenwu Ou, Zhirong Wang, and Xiaoyan Zhu, first published 23-27th Jan 2018 by the International World Wide Web Conference Committee. The full paper can be read here.

Most large-scale online platforms or apps incorporate multiple scenarios in to their system that can include services such as search, advertising, and recommendations. Alibaba’s Taobao, for instance, is a huge Chinese e-commerce platform where users can search for and buy products through querying or bookmarking goods, as well as based on recommendations.
A common feature of these services is ranking strategies that serve as a fundamental function to provide a list of ranked items to users. These strategies focus on specific scenarios that cover different aspects of the way in which users interact with online platforms.
Alibaba’s approach is to apply their new multi-scenario ranking optimization model, and Taobao’s performance in this area has shown a marked improvement over more traditional approaches.
Scenario Ranking
Optimization of single scenarios cannot guarantee the global optimal performance of an entire platform. The collaboration of strategies in different scenarios can overcome this and result in better overall performance.
Take the following illustration as an example, showing the competition between two sellers selling snacks on a beach. The top figure shows the initial location, where people in red buy snacks at A and people in blue buy snacks at B. The middle figure shows that when A moves right, and so covers more customers, then more sales can be made. The bottom figure indicates the optimal solution to this non-cooperative game, where the two sellers compete with each other and both are located at the center of the beach. Nevertheless, the total income of the two sellers is not optimal in this scenario as the people in grey are beyond the scope of the sellers.
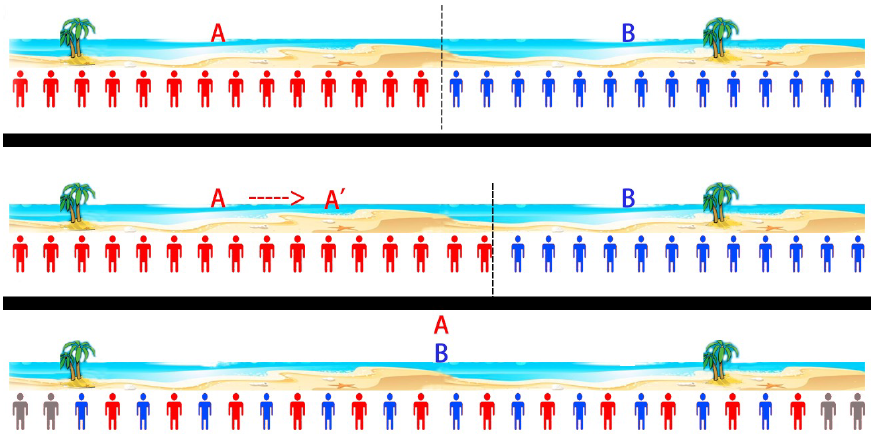
Competition between two sellers (A and B) selling snacks along a beach
The simple example above illustrates that collaboration between scenarios is extremely important if the overall objective is to optimize the total system returns. This is the case with e-commerce platforms, where multiple different scenarios are utilized.
Although machine learning techniques have been widely applied in the optimization of ranking strategies to improve services, a ranking strategy within just one scenario can only be used to optimize its own metric and does not consider the correlation between scenarios. In this case, metrics include the Click Through Rate (CTR), Conversion Rate (CVR), and Gross Merchandise Volume (GMV).
Not a team player
The typical approach mentioned above to scenario ranking has its limitations. Furthermore, because the independent optimization in one scenario uses its own user data but ignores data from other scenarios, this approach is unable to model correlations between scenarios.
By analyzing the user logs of millions of Taobao users, it was found that there was a 25% conversion from the main search to the in-shop search, while there was only a 9% conversion from the in-shop search to the main search. This type of scenario conversion also occurs amongst search, advertising, and recommendation scenarios, and shows the limitations of independent scenario optimization. Therefore, multi-scenario ranking optimization that collaborates across multiple scenarios is a much more effective approach.
Multi-Scenario Ranking Optimization
Optimizations to improve the overall performance of multiple ranking strategies across different scenarios is a relatively new approach. The team at Alibaba proposes the Multi-Agent Recurrent Deterministic Policy Gradient (MA-RDPG) model, which jointly optimizes ranking strategies for different scenarios through collaboration and the sharing of an identical goal.
Moving back to our previous example again, multi-scenario ranking helps to provide the optimal solution by providing the best locations to both sellers while also accessing the whole market, as shown below.

Competition between two sellers using multi-scenario ranking optimization
This model formulates multi-scenario ranking as a fully cooperative, partially observable, multi-agent sequential decision problem and incorporates the following:
- A communication component for passing messages.
- Several private actors (agents) for making actions for ranking.
- A centralized critic for evaluating the overall performance of the co-working actors (agents).
In this model, each scenario is considered an actor (agent). Collaborations between actors are undertaken by sharing a global action-value function (the critic) and passing messages that encode historical information across scenarios. In addition, the model’s centralized global critic network evaluates the overall rewards. The overall model architecture is illustrated below.
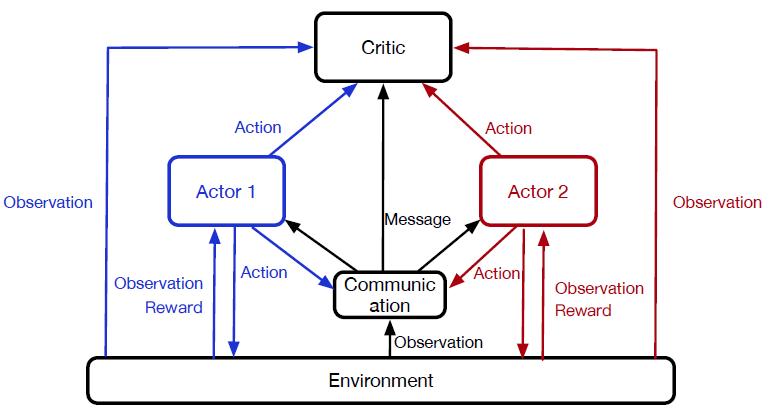
MA-RDPG model architecture overview
The sequential process starts when a user enters a scenario and browses, clicks on, or buys goods. The search system (the model) then changes the ranking strategy by adjusting the ranking algorithm when the user navigates into a new scenario or issues a new request. This process is repeated until the user leaves the system, so the current ranking decision affects any future decisions.
MA-RDPG Ranking in Taobao
Alibaba has applied this approach to evaluate online settings on their huge e-commerce platform Taobao. Results show that this proposed model provides significant improvements against baseline ranking algorithms outcomes in terms of overall performance. Baseline ranking algorithms comprise the Empirical Weight (EW) algorithm, which applies a weighted sum of the feature values with empirically adjusted feature weights, and the Learning to Rank (L2R) algorithm, which learns feature weights by a point-wise learning-to-rank network.
This case study illustrates that, in Taobao, the main search scenario supports the in-shop search scenario and thereby targets more future overall rewards. The main search with MA-RDPG ranks items from a global perspective, so that not only its own immediate rewards (i.e. a direct purchase) are considered, but also future potential purchases during an in-shop search.
Ranking is a fundamental issue in many applications, and an effective ranking strategy can significantly improve user experience and system performance. By using joint ranking optimization across multiple scenarios, Alibaba has improved performance over traditionally used algorithms for the e-commerce platform Taobao. Further work is needed across other domains to fully realize the potential of this approach.
The full paper can be read here.
. . .
Alibaba Tech
First hand, detailed, and in-depth information about Alibaba’s latest technology → Search “Alibaba Tech” on Facebook
