- Reading Aloud: Sequential Memory for Speech Synthesis
This article is part of the Academic Alibaba series and is taken from the paper entitled “Deep Feed-forward Sequential Memory Networks for Speech Synthesis” by Mengxiao Bi, Heng Lu, Shiliang Zhang, Ming Lei, and Zhijie Yan, accepted by IEEE ICASSP 2018. The full paper can be read here.

Text-to-Speech (TTS) systems are an essential part of human-computer interactions. For current Internet-of-Things (IoT) devices, such as smart speakers and smart TVs, speech is the most efficient and accessible approach for both the user and device to understand each other through instructions and feedback. However, one issue that commonly hampers user experience is machine generated speech being perceived as unnatural or non-human-like by users. Overcoming this obstacle has been a major challenge for TTS systems to date.
Recent developments in neural network-based parametric speech synthesis systems have allowed for substantially higher-quality, natural-sounding speech. However, when applied to IoT devices that have limited computational resources and require real-time feedback, the issue arises of how to reduce the computational requirements of the system. This has proven to be a highly complex issue.
To overcome these constraints, the Alibaba tech team proposes the Deep Feed-Forward Sequential Memory Network (DFSMN). It is designed to replace the Bidirectional Long Short-Term Memory (BLSTM) used in neural network-based parametric speech synthesis systems. An outline of the system is illustrated below.
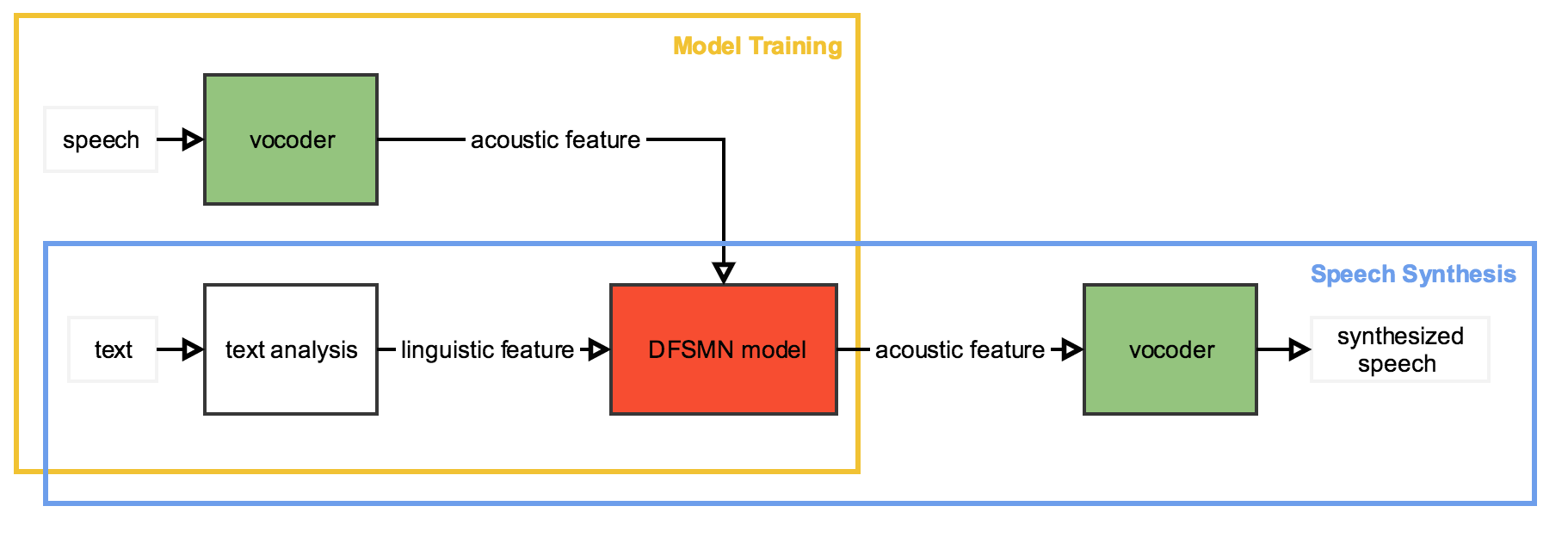
The DFSMN is a feed-forward neural network, meaning that it can be more efficiently and stably trained in comparison with the BLSTM. Additionally, the DFSMN is flexible in terms of context dependency. For instance, the order of memory blocks can be narrowed so that only the near history and future are considered by the network when sequences are short or latency is essential. Alternatively, when sequences are long or latency is less important, the order of memory blocks can be enlarged to fully utilize long-term dependencies, although this affects system efficiency.
The Alibaba tech team has shown that the DFSMN can achieve the same results as the BLSTM, but with a 4-times smaller model size and a fourfold increase in efficiency. These results illustrate that the DFSMN shows promise for effective application in IoT devices, where memory and computational efficiency offers huge advantages over the BLSTM approach.

Read the full paper here.
. . .
Alibaba Tech
First hand, detailed, and in-depth information about Alibaba’s latest technology → Search “Alibaba Tech” on Facebook
