- Maximizing CPU Resource Utilization on Alibaba's Servers

Computing resources are essential to both online services and offline batch jobs. But a surprising amount of resources are sitting idle at any given time. According to Geithner and McKinsey, global servers only use 6 to 12 percent of their CPU. For Alibaba's online services, average daily utilization rates were only about 10 percent until the tech team introduced their colocation solution to address the issue.
Through colocation technology, Alibaba can effectively utilize those previously underutilized resources. This is achieved by exploiting the different properties of online services and batch jobs. By employing colocation on their servers, Alibaba has increased their CPU utilization from 10 percent to up to 40 percent – an impressive 30 percent increase.
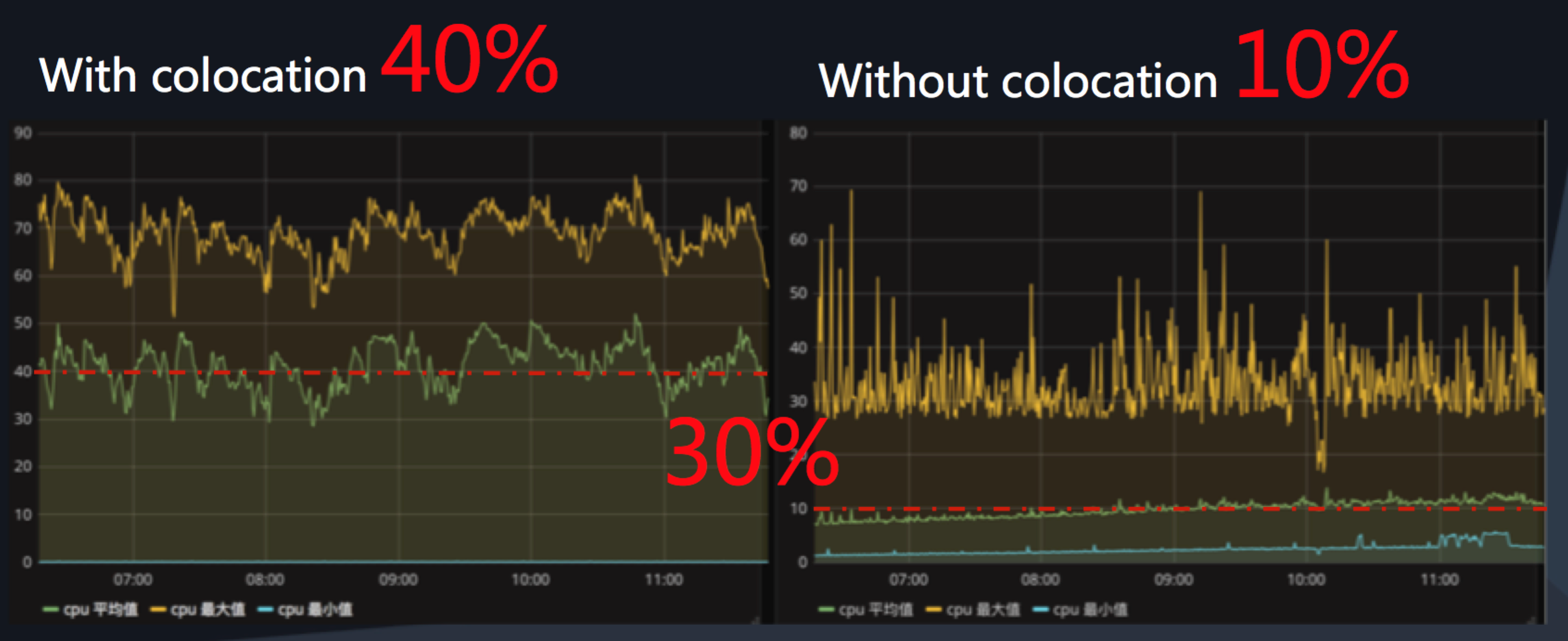 Colocation boosts cluster resource usage by 30 percent
Colocation boosts cluster resource usage by 30 percent
Alibaba first started researching colocation technology for large-scale use in e-commerce in 2014. The first large-scale use came in 2017, when 20 percent of traffic during the Double 11 Global Shopping Festival was handled using the technology.
 Alibaba's colocation technology: from research to implementation
Alibaba's colocation technology: from research to implementation
Better CPU Utilization Through Colocation
Colocation works by scheduling different task types to the same physical resource. This means combining clusters and using control methods such as scheduling and resource isolation to fully utilize resource capabilities. Alibaba's colocation technology does this while safeguarding system landscape optimization (SLO).
 Colocation technology and CPU resources
Colocation technology and CPU resources
To be eligible for colocation, tasks must:
- Be able to be divided by priority levels
It is important to have different priority levels so that high-priority tasks can take over resources from low-priority tasks when necessary. - Have complementary resource allocation
This means that different task types require a different amount of resources at different times.
Colocation Applied to Online Services and Batch Jobs
Colocation can be applied effectively to online services and offline batch jobs by exploiting the different computing requirements of each.
- "Online services" simply refers to any kind of Internet-based service. For Alibaba Group, this includes online platforms such as Alibaba.com, AliExpress, and Tmall, and the online activities of these platforms, such as promotional events.
Online services require large amount of resources at peak times – such as during Alibaba's Double 11 Global Shopping Festival – but require far fewer resources outside these periods. This means that outside of peak periods, large amounts of resources can go unused. Global servers only use 6 to 12 percent of their CPU. Online service usage is higher during the day than during the early hours, and online services must continue uninterrupted.
- "Batch jobs" are tasks such as data analysis, which require computing resources but have relatively low latency sensitivity requirements.
Batch jobs take up a large amount of resources, especially CPU time. The peak time for batch jobs is early in the morning.
Online services and batch jobs therefore meet the eligibility criteria for colocation:
- Online services are higher priority than batch jobs because they must continue uninterrupted. Batch jobs are lower priority because they are less sensitive to delays.
- The peak time for batch jobs is the early hours of the morning, while online services are more likely to peak during the day, making them complementary.
A useful way to understand how colocation better utilizes CPU resources for online services and batch jobs is by using the metaphor of sand and stones.
Online service resource demands can be likened to stones held within a container. Outside of peak times, an online service only needs to use the stone resources within the container and does not need to use the gaps between the stones.
Batch jobs demands can be likened to sand that fills the gaps between the stones in the container. As online services do not usually need to use this space, the batch jobs sand can fill this space. But when demand for online services rises, the batch-job sand leaves the container so online services can use the extra resources. In this way, the higher priority task type – in this case online services – can continue uninterrupted.
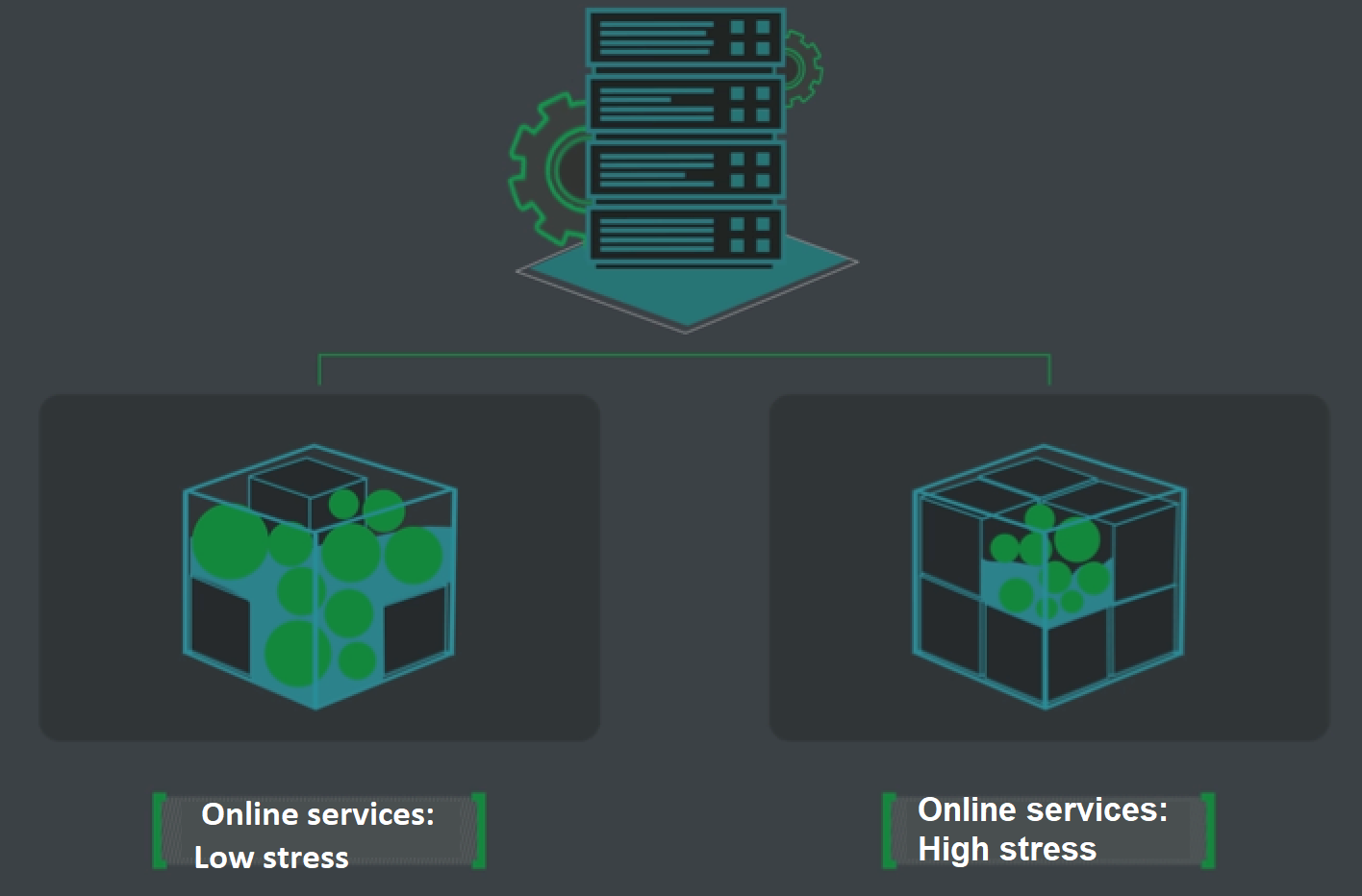 When demand for online services is high, online services use more resources. The green "stones" represent online services while the blue "sand" represents batch jobs.
When demand for online services is high, online services use more resources. The green "stones" represent online services while the blue "sand" represents batch jobs.
Calculating the Benefits of Colocation
The amount of resources that colocation saves is calculated according to a simple formula.
Suppose that a data center has "N" servers, and the utilization rate ("R") increases from R1 to R2. Without taking any other restrictions into account, the number of servers ("X") that can be saved is calculated as follows:

It follows that if you have 100 thousand servers and your resource usage rate increases from 28 percent to 40 percent, you can save 30 thousand servers. In other words, colocation can save up to 30 percent of resources.
This is corroborated in a 2015 paper published by Google entitled "Large-scale cluster management at Google with Borg". In this paper, Google describes a solution using similar technology to the colocation solution developed by Alibaba, and notes that they were able to save 20 to 30 percent of their computing resources using this solution.
Colocation Scheduling Architecture
The following figure shows the architecture of Alibaba's colocation scheduling solution.
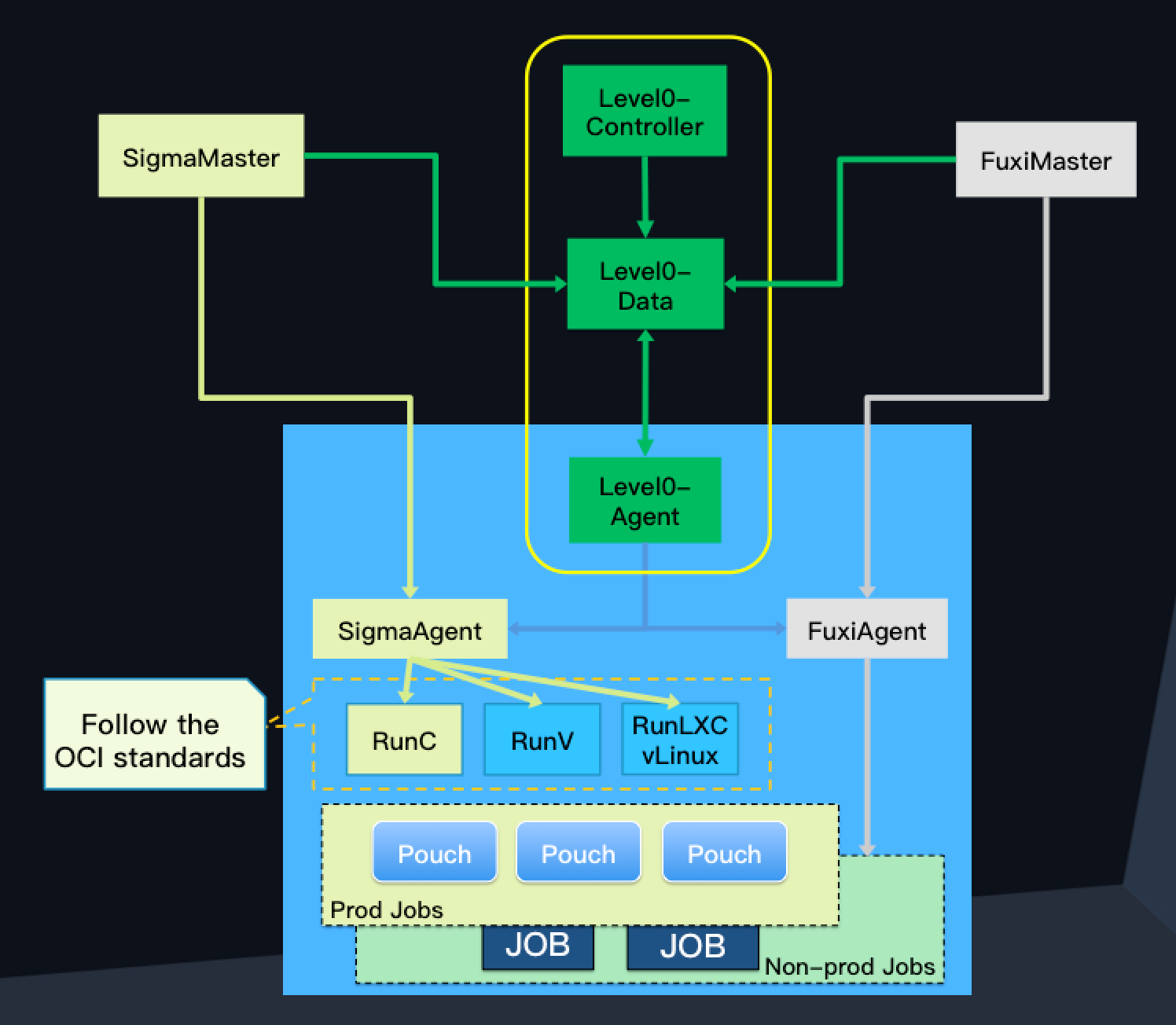 Colocation scheduling architecture
Colocation scheduling architecture
The three key aspects of the solution are two scheduling clusters, which operate autonomously, and the Level0 mechanism which coordinates between them:
- Sigma manages scheduling for the online services container.
- Fuxi manages data processing and batch jobs.
- The Level0 mechanism is comprised of Level0- Data, Level0- Agent, and Level0- Controller, and enables the SigmaMaster and FuxiMaster schedulers to work together.
Sigma
Sigma manages scheduling for the online services container. It:
- Is compatible with the Kubernetes API.
- Uses the Ali Pouch container, compatible with OCI standards.
- Has already been used for large-scale purposes by Alibaba for several years. It has also been used during the Alibaba Double 11 Global Shopping Festival.
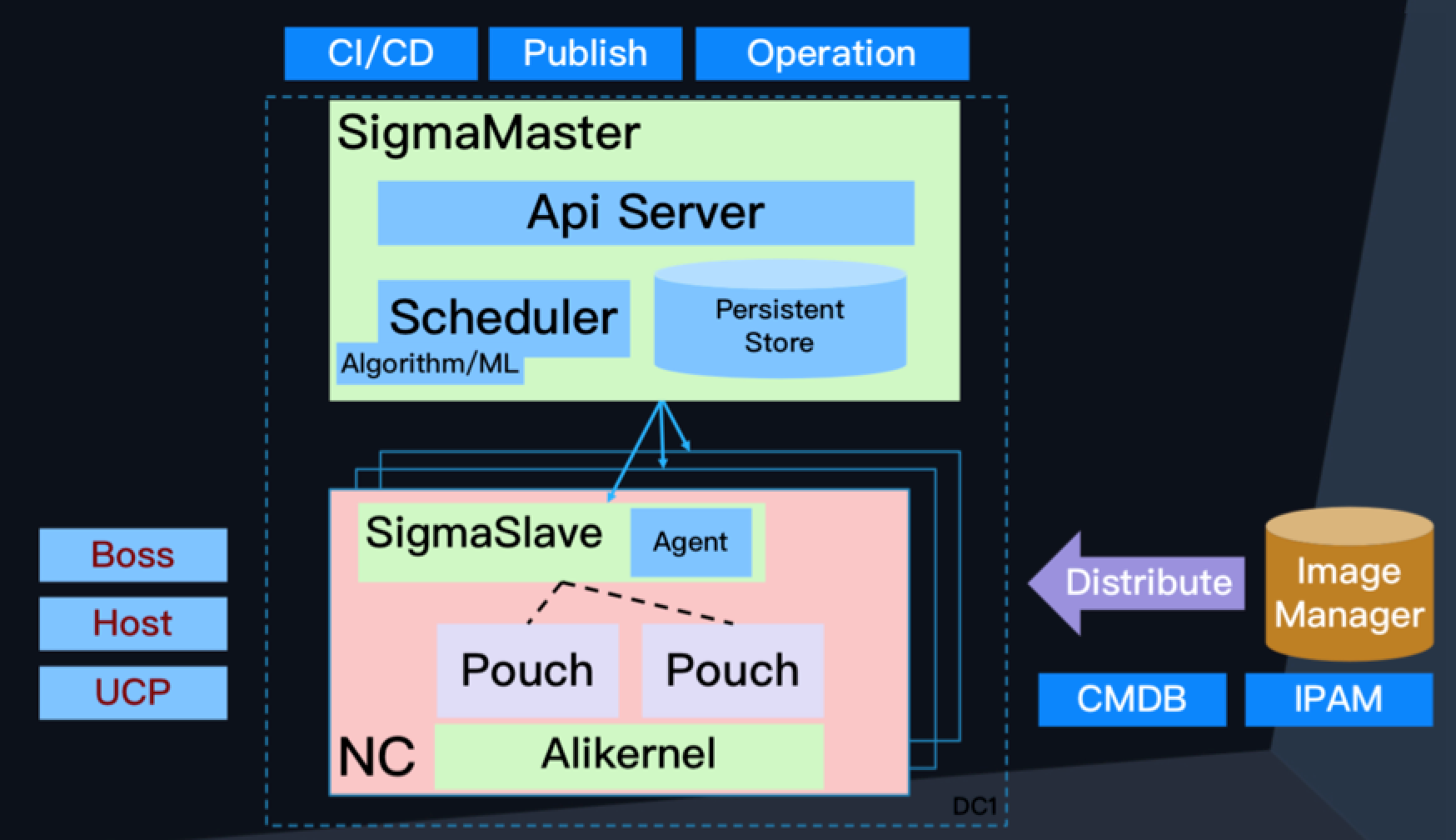 Sigma architecture
Sigma architecture
Fuxi
Fuxi manages batch jobs. It is:
- Used for vast amounts of data processing and complex large-scale computing type applications.
- Provided with a data driven multilevel pipelined parallel computing framework, which is compatible with MapReduce, Map-Reduce-Merge, Cascading, FlumeJava and other programming modes.
- Highly scalable. It supports hundreds of thousands of levels of parallel task scheduling, and can optimize network overheads according to data distribution. It automatically detects faults and system hotspots, it restarts failed tasks, and it ensures stable and reliable completion of operations.
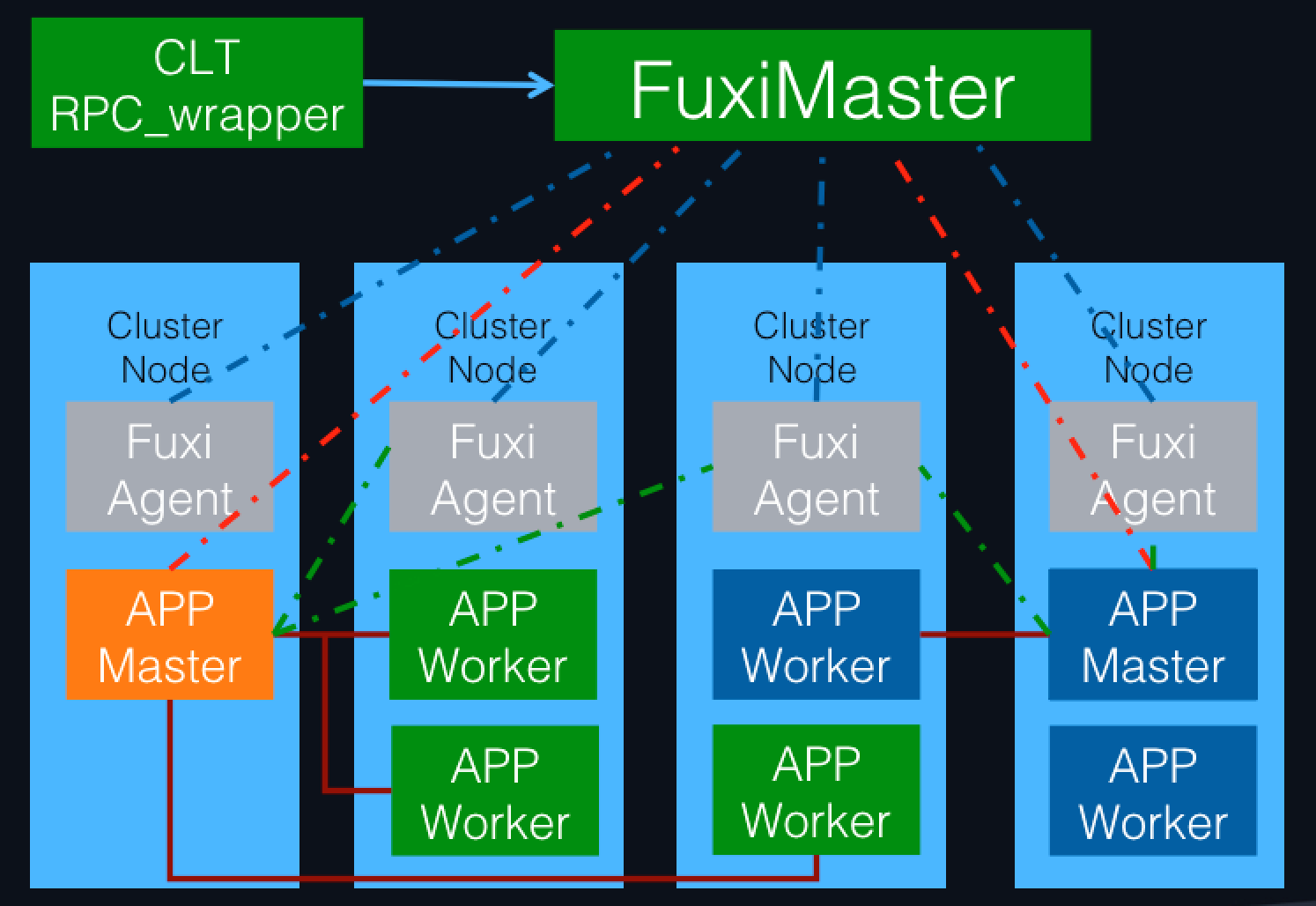 Fuxi architecture
Fuxi architecture
Level0 Mechanism
The Level0 mechanism, shown in the diagram below, coordinates and manages the cluster for smooth and stable operations. The mechanism manages:
- Colocation clusters
- Resource matching between each scheduling tenant
- Strategies for everyday use and use during large-scale promotions
- Exception detection and processing
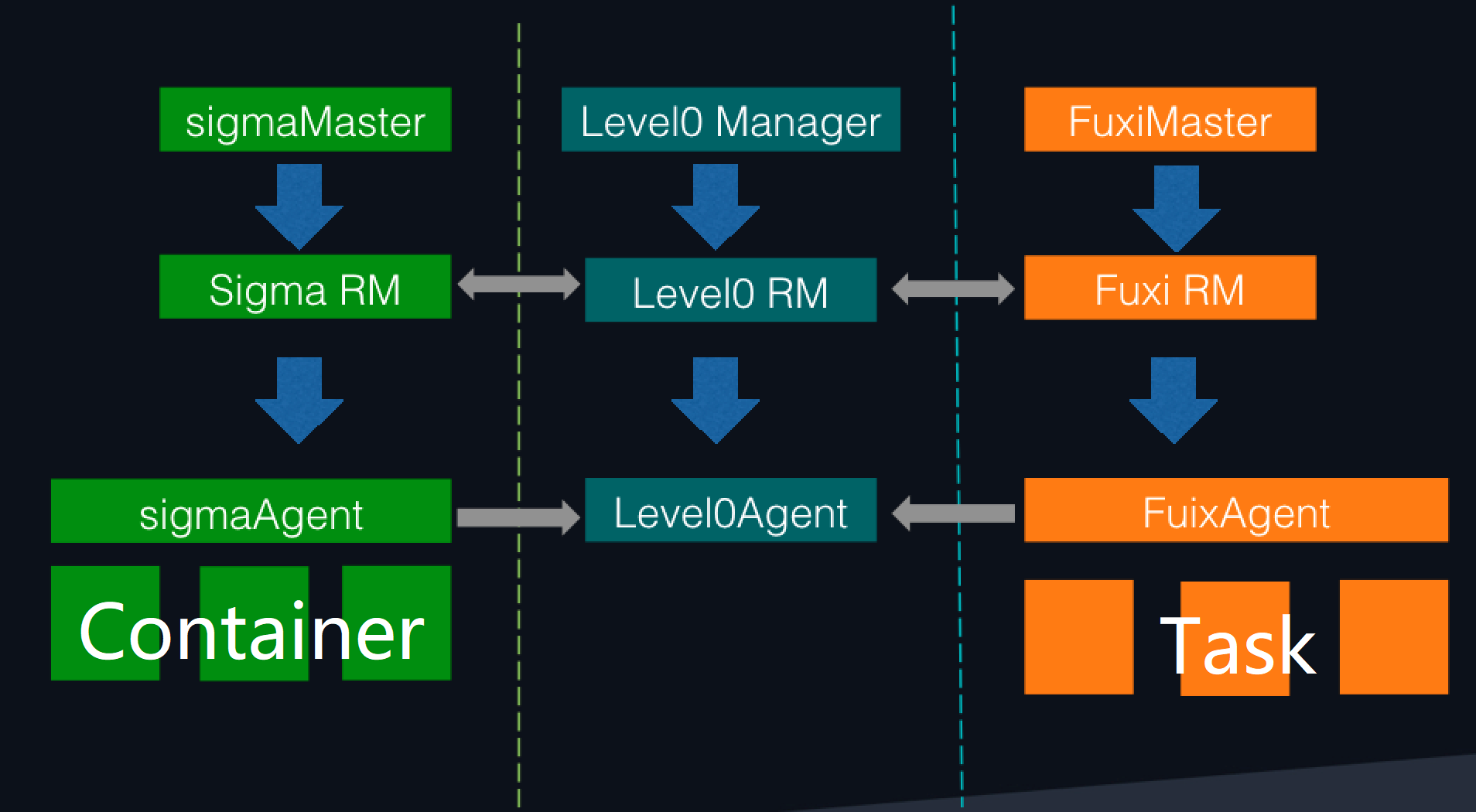 Level0 mechanism
Level0 mechanism
Colocation Resource Isolation
For colocation to work effectively, it is essential for resource isolation to be carried out properly. If resource isolation is not carried out effectively, then competition for resources can not be resolved effectively.
This can then lead to issues with online services. At best, this can damage the quality of user experience. At worst, it can mean online services fail to be provided.
The following two approaches can be taken to avoid issues with resource competition:
1.Scheduling
2.Kernel isolation
Scheduling
Scheduling uses resource representation technology to predict and plan resource demands before resource competition arises. The aim of scheduling is to reduce the probability of resource competition arising. Scheduling can be constantly optimized.
Scheduling can be optimized according to the following methods and considerations:
- Daily time-division multiplexing
- Promotion time-division multiplexing
- Lossless downgrading
- Batch job selection
- Dynamic memory
- Computer storage separation
Daily Time-Division Multiplexing
For online services and batch jobs, the peaks and troughs of resource demands occur at different times of the day. Time-division multiplexing can therefore be used on a daily basis to improve resource utilization.
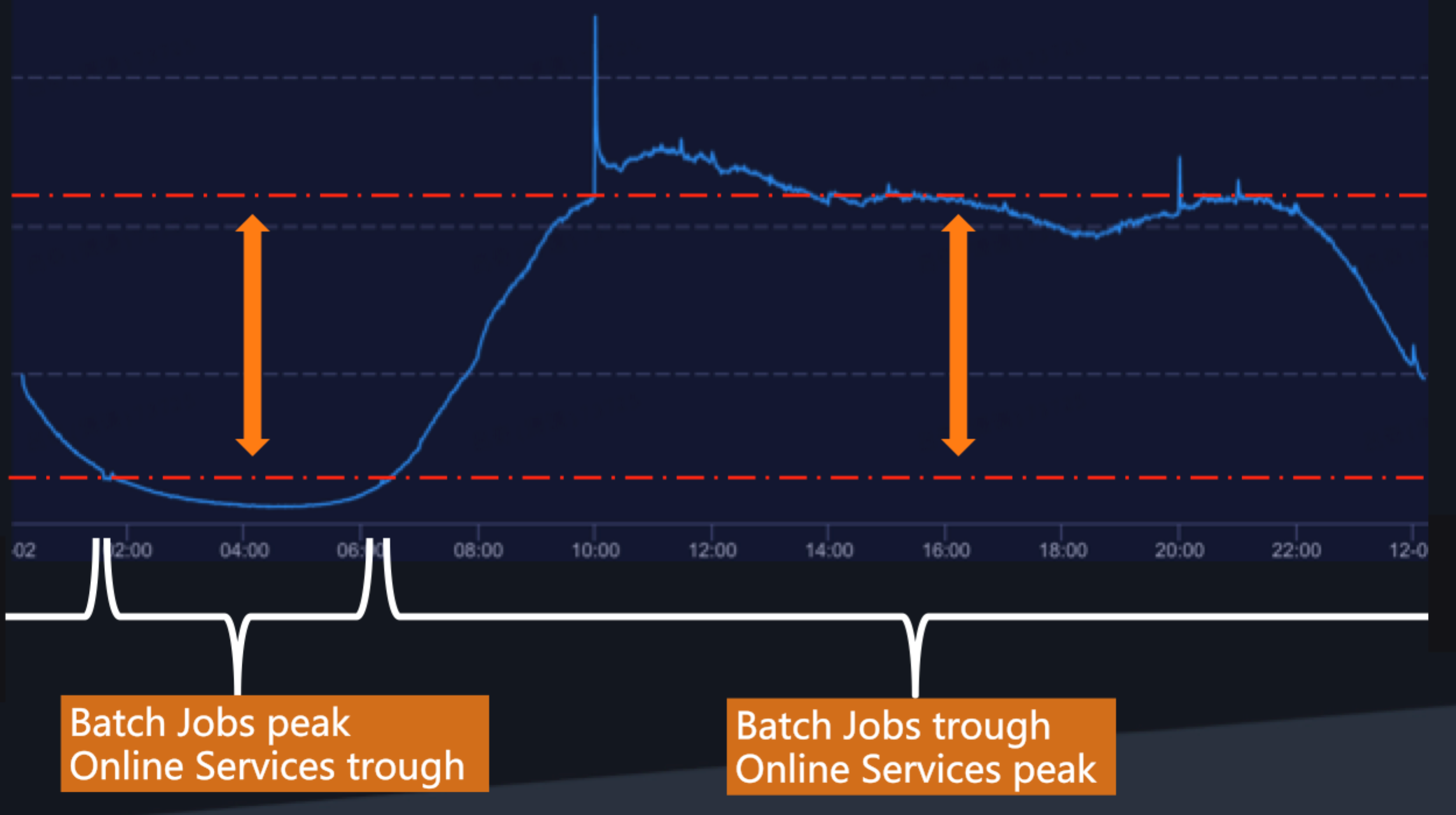 Peaks and troughs for online services and offline batch jobs
Peaks and troughs for online services and offline batch jobs
Promotion Time-Division Multiplexing
The e-commerce business involves huge online promotions, such as the Double 11 Global Shopping Festival. During large-scale promotions, or stress testing, pressure on resources will be quite a few times higher than during normal operations. If at that time, we reduce resources for computing tasks and give all those resources to online services, then we can deal with that short term burst of demand for resources quite effectively.
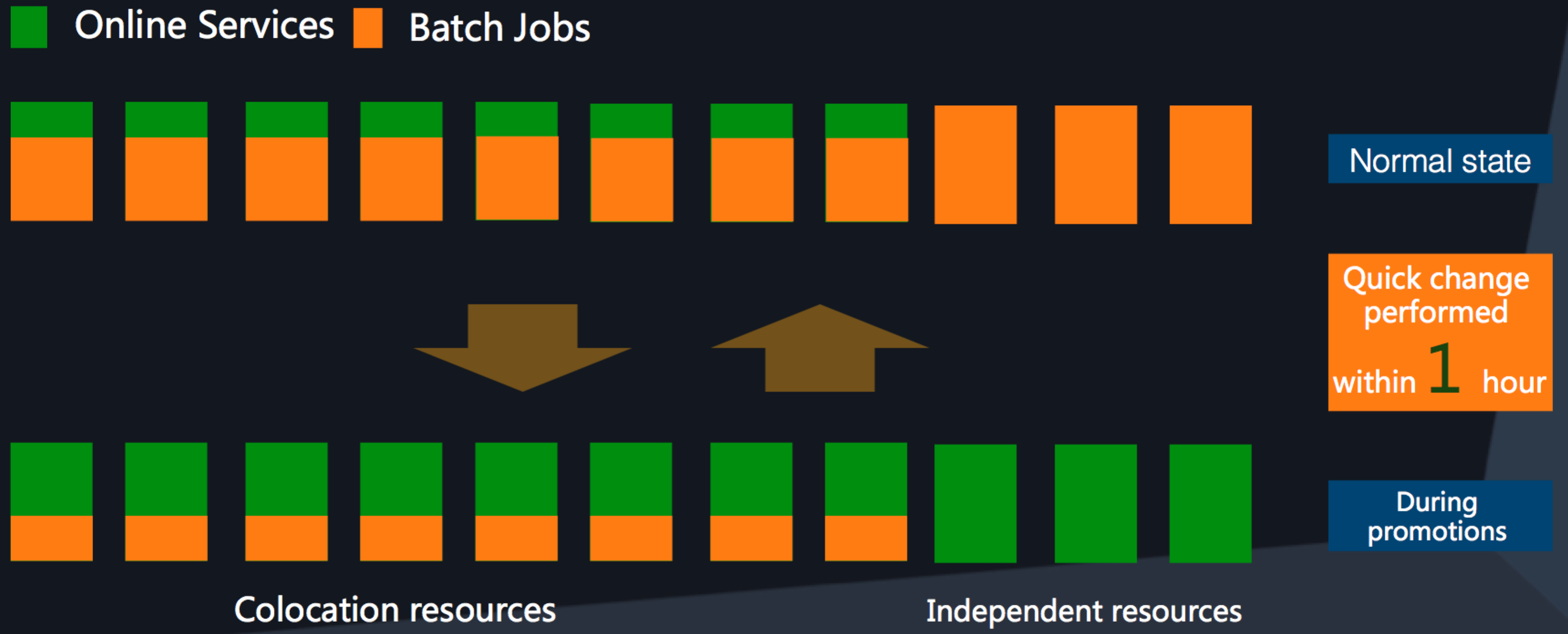 Allocation of colocation resources according to demand
Allocation of colocation resources according to demand
Lossless Downgrading
When downgrading batch jobs, the impact should be reduced as much as possible. For lossless downgrading, attention should be paid to the downgrade plan.
Because online services do not usually use many resources, adding 70 percent of computing task resources takes less than three minutes. This means that in the first five minutes after a downgrade, the impact of batch jobs on online services should not be too large.
Another issue is minute-level recovery. If minute-by-minute recovery is implemented successfully, then there will only be effects at the real peak points. As the peak point period is very short, the effect will be minimized.
Batch job selection
Before we used the metaphor of sand to describe batch jobs. But even grains of sand vary in size. To make sure gaps in resources are used without overflowing, we need to filter and select the sand. This can mean:
- Making a resource representation for the task or job, and analyzing the quantity of resources that will need to be consumed.
- Using Level0 to obtain the exact surplus computing resource capacity of the host.
- Selecting the task or job that best meets the conditions and will reduce resource competition.
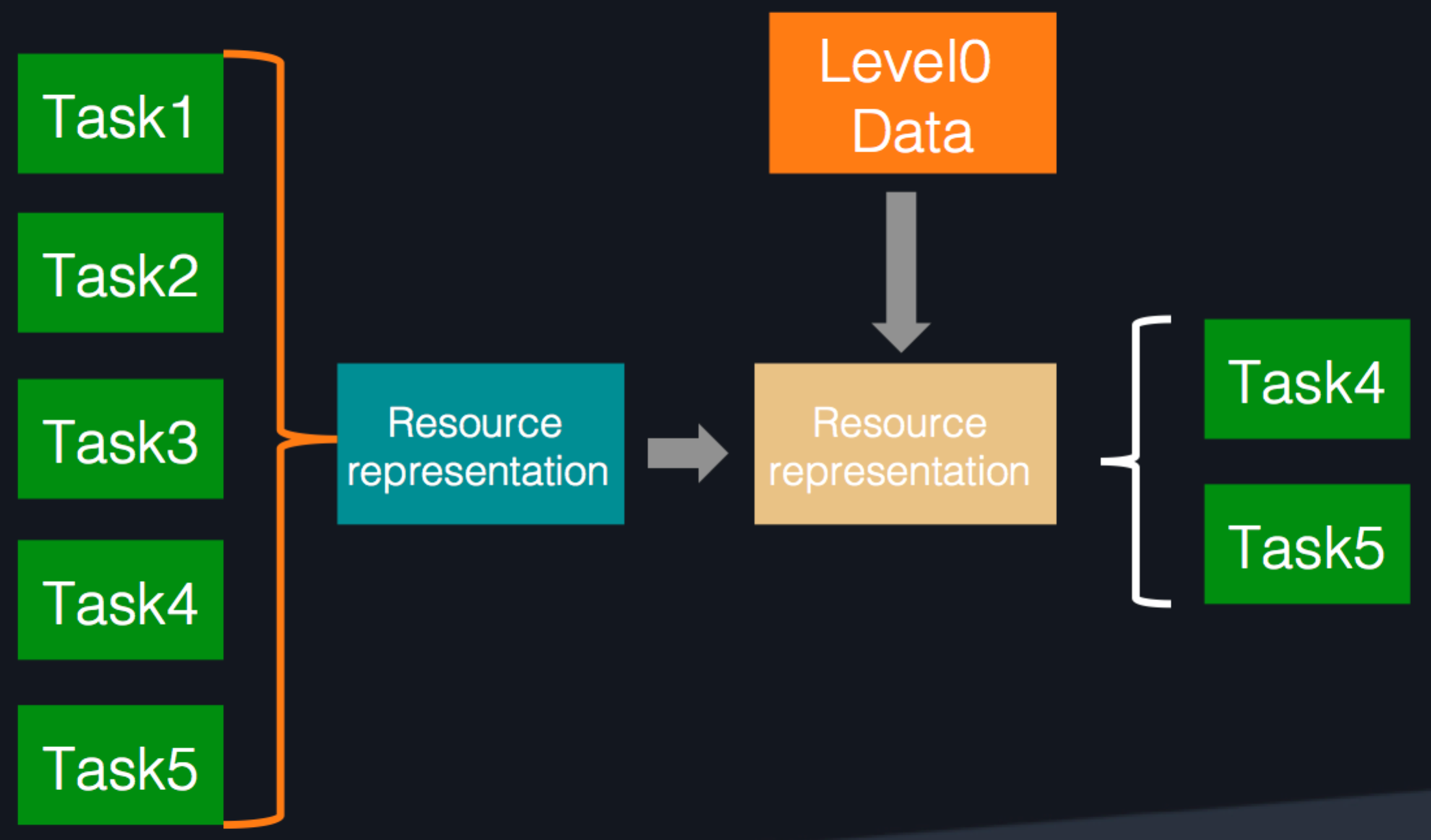 Computing task selection process
Computing task selection process
Dynamic memory
As previous memory resources did not consider colocation, internal memory and CPU are matched to the original demands of online services, without any surplus internal memory.
Due to increasing demand, internal memory reached a bottleneck, and static distribution of internal memory was no longer sufficient. To address this, dynamic distribution of internal memory was introduced. This can mean:
- Dynamic adjustment of the amount of internal memory that computing tasks use.
- Automatic adjustment of batch jobs memory usage, through migration or a kill task, when stress on online services increases.
- Killing computing tasks with lower priority first if the overall unit is out-of-memory (OOM).
Computer storage separation
Different storage solutions are used for online services and batch jobs:
- Online services prioritize input/output per second (IOPS) but do not use a large storage capacity, so small SSD drives are used for storage.
- Batch jobs prioritize storage but not IOPS, so large HDD drives are used for storage.
When using colocation, if the local drive is still being used to process data, but batch jobs are mixed together, then scheduling becomes significantly more complicated. To resolve this, we need to make a virtual memory pool from the local drives.
In this way, we can access different storage devices according to demand through remote access.
Alibaba has also started to build 25G network capacities on a large scale. This will improve overall network capability. It will also allow remote access to become as fast as local access.
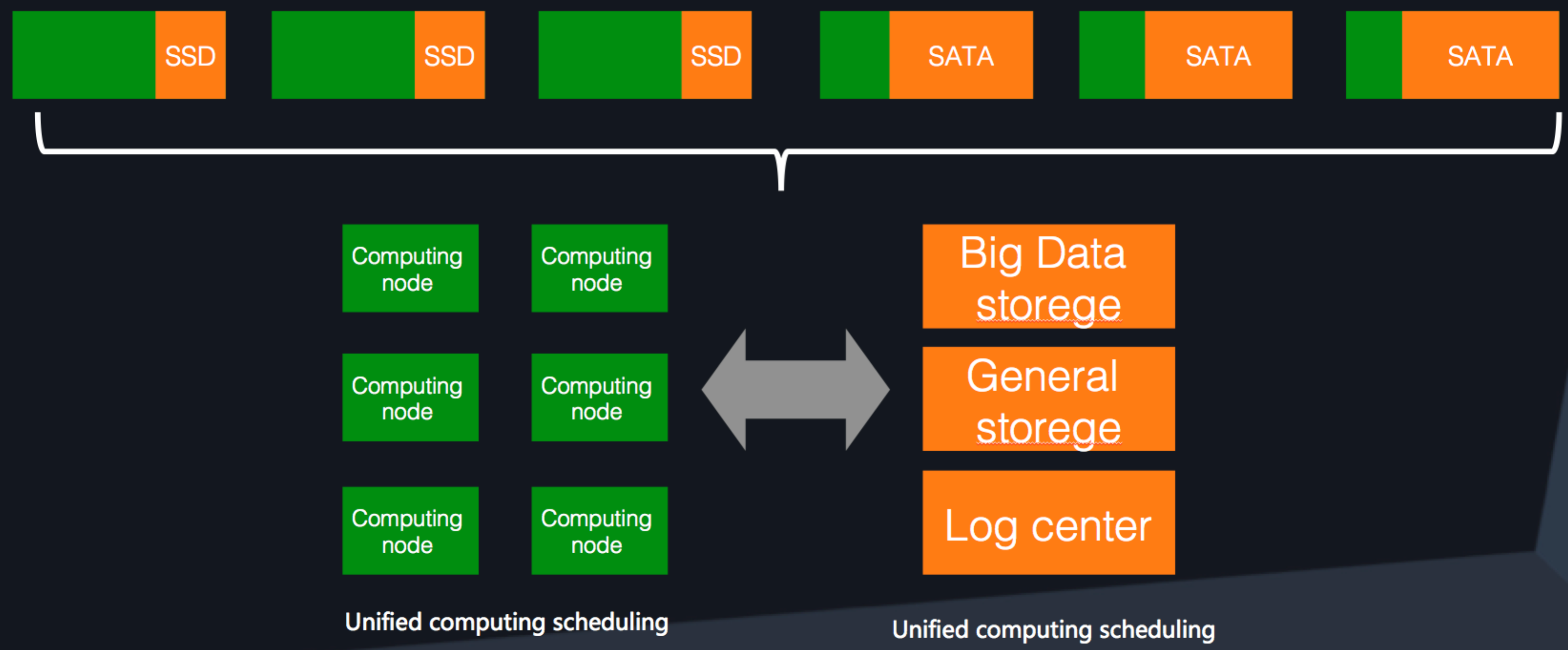 Computing and storage scheduling
Computing and storage scheduling
Kernel Isolation
If resource competition occurs, task prioritization can be used to decide how to prevent impact on high priority tasks and minimize impact on lower priority tasks. This is a last-resort measure to be taken in extreme circumstances.
Kernel isolation can be implemented according to the following methods and considerations:
- CPU scheduling optimization
- Memory protection
- IO hierarchal constraints
- Network traffic control
CPU scheduling optimization
This is the most important kernel isolation item. When stress rises for CPU online services, batch jobs must withdraw within milliseconds.
 As the red arrows show, when online services need more resources, batch jobs must immediately use less resources
As the red arrows show, when online services need more resources, batch jobs must immediately use less resources
CPU scheduling optimization includes:
- CPU resource taking
This means assigning priority levels according to CGroup. High priority tasks can take timeslots from low priority tasks.
- Avoid HT (noise clean)
This means avoiding offline tasks being scheduled to HTs adjacent to online tasks and ensuring that offline tasks scheduled to HTs adjacent to online tasks are moved after being woken.
- L3 cache isolation
Use the BDW CPU featured CAT to carry out cache access traffic control. In this way the CPU use of low-priority tasks can be limited.
- Memory bandwidth isolation
Memory bandwidth includes implementing strategized adjustments according to real-time monitoring and controlling CFS bandwidth by adjusting the operation timeslot length for batch jobs. Giving tasks a shorter timeslot allows high-priority batch jobs to use more CPU resources.
Memory protection
Memory protection:
- Tries to avoid online tasks being affected by memory recovery through memory recovery isolation.
- Allocates priorities according to different CGroups, increases the recovery mechanism within groups, and determines importance of memory recovery according to priority level.
- Kills tasks starting from the lowest priority if a unit is OOM.
IO hierarchal constraints
A blkio controller as well as IOPS and bits per second (BPS) constraints have been added for file-level IO bandwidth isolation (upper level). File-level low bandwidth thresholds (lower level) allow use of surplus free bandwidth once the low bandwidth threshold has been crossed. The metadata throttle limits specific metadata operations, such as deleting large amounts of small files at once.
Network traffic control
Network traffic control includes bandwidth isolation, which includes local bandwidth isolation and bandwidth isolation between Pouch containers.
It also includes bandwidth sharing, which is divided into gold, silver, and bronze levels. Shared bandwidth can exist offline, and bandwidth can be taken according to priority.
Conclusion
After four years of development, colocation managed 20% of Alibaba’s Double 11 Global Shopping Festival's traffic in 2017. Over the coming year, colocation will continue to evolve.
Colocation will be able to be used in more diverse applications such as real-time computing, GPU or FPGA. Colocation will also increase in terms of scale. For resource representation capacity, deep learning will be used to improve prediction accuracy and utilization rates.
Optimization of prioritization systems will further improve scheduling capacity. Scheduling will then be performed by priority levels rather than by online services and batch jobs. In the future, colocation can become a universal capability for scheduling systems.
Alibaba Tech
First hand, detailed, and in-depth information about Alibaba’s latest technology → Search “Alibaba Tech” on Facebook
