- Zillions of Homepages for Zillions of Customers
Personalization algorithms empower shopper purchasing decisions

As portals of first impressions, E-commerce app and website homepages play a crucial role in the processing, delivering and scheduling of user traffic. A homepage that is optimized to suit the individual profiles of shoppers also improves conversion rates for product pages and sales, decreases overall bounce rates, and creates user experiences that improve repeat purchase rates. Personalized homepages are also effective in driving sales during important promotion periods, such as Alibaba’s Double 11 Global Shopping Festival (the famous “Singles’ Day”) into which hundreds of millions of shoppers went for the year’s best deals on China’s biggest E-commerce platforms like Taobao.com and Tmall.com.
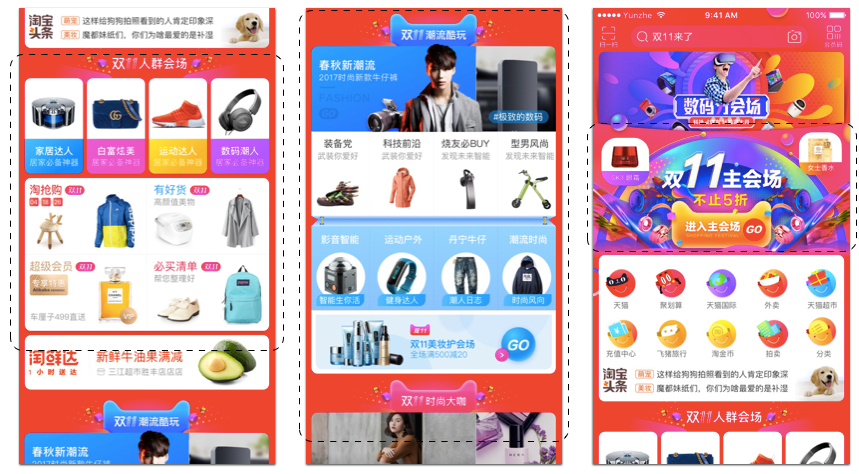 Recommendations displayed on the Taobao mobile app homepage on Double 11
Recommendations displayed on the Taobao mobile app homepage on Double 11
The screenshot on the left shows the standard AIO portal which includes daily AIO scenarios (Taoqianggou, Youhaohuo, list, etc.), as well as customized sub-market categories for the shopping festival. The screenshot in the middle shows the AIOplus scenario cards as the standard portal, including five cards covering a distribution of over 20 daily businesses. The screenshot on the right shows a WYSIWYG portal to the campaign and uses a dual carousel. In terms of overall UV traffic management on Double 11, the homepage did very well, servicing for tens of millions of UVs.
The relevant homepage personalization algorithms primarily involve the graph embedding model and Deep CrossResNet model. Also a graph embedding framework and XTensorflow platform were built, which provides the framework for other recommendation scenarios and significantly improve the performance.
The Framework
Graph Embedding Deep Recall
During the course of developing the recommendation system, two core issues appeared: the long-tail coverage of users and the cold start of new items. The data scalability bottleneck in these two dimensions has always posed a big challenge to recommendation system engineers. However, Toabao’s innovative frameworks, based on graph embedding, deployed sequential click behavior to construct the graph in the recalling phase. These frameworks also generate multi-order (generally 5 or more orders) potential interest information by the "virtual-sampling" of user behaviors in conjunction with deep random walk technology to expand the long-tail recall of items interesting to the user. Furthermore, they take advantage of side information-based deep networks for generalized learning, which to an extent solves user coverage and cold start issues. Meanwhile, the combination of sampling technology for virtual samples and generalized learning enabled by deep models increases the number of recalls for item discovery by the user, and improves the degree of diversity and discovery.
In pursuit of better solutions, theS³ Graph Embedding Model was utilized for generating the candidate recalls.
The evolution of the S³ Graph Embedding Model is mainly reflected in three perspectives:
- Sequence Behavior
- Sub-graphing
- Side-information
Building the Naive Version
- The first step in the application of graph embedding to the recommendation field was to build a heterogeneous network. In order to simplify the problem, the original Swing algorithm created by @Xuanmu, a member of the recommendation team, was used to calculate the similarity of items.
- The second step was to sample the network of items in random walk. Node2vec was used for reference, made a trade-off between the local stability and global scalability of the item graph, and balance the diversity and accuracy in the candidate matches.
- The third step, after sampling and procuring the item sequence, was to learn the embedding representation. Negative sampling in the-state-of-the-art SkipGram model was optimized to solve the large-scale dictionary problem.
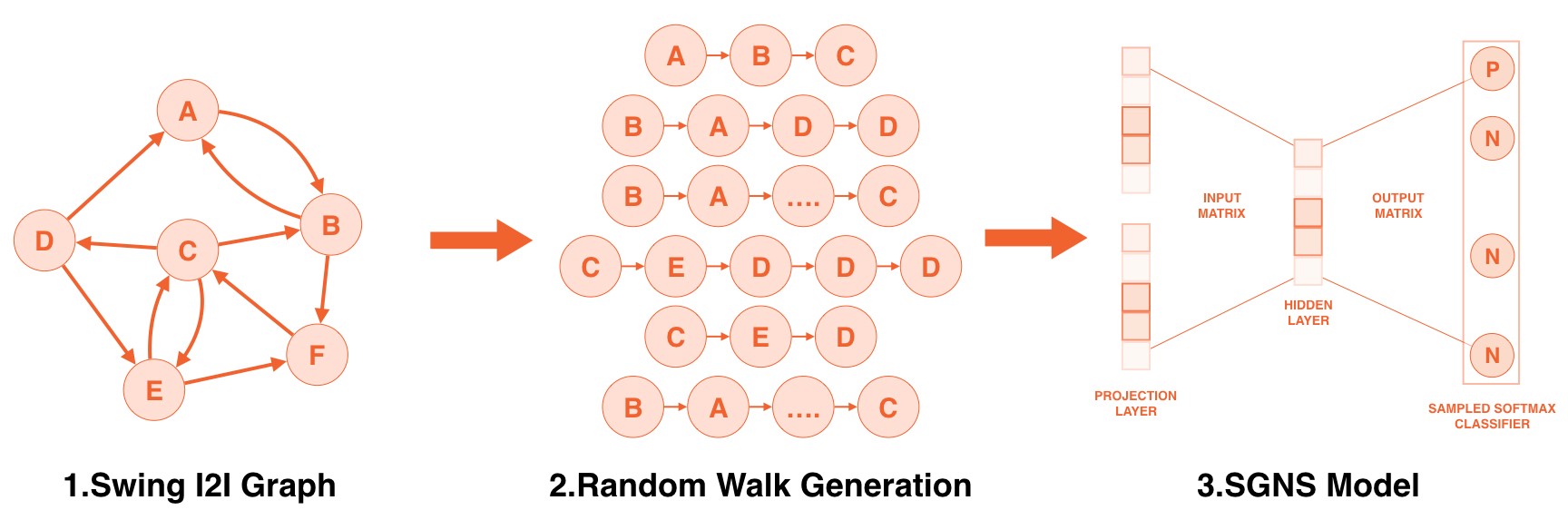 As shown in the figure, graph embedding's similarity calculation incorporates a high-order information against Swing's one-order extension
As shown in the figure, graph embedding's similarity calculation incorporates a high-order information against Swing's one-order extension
Sequence + Side-Information
Breakthroughs in enriching diversity and improving accuracy were made in three respects:
(1) Embedded modeling directly through the behavior sequence in the user session.
(2) After constructing the graph with the overall user behaviors, a transition rate connection edge like tf-idf was introduced to overcome the Harry Potter hotspot issue (a few items are too popular for dominating the results of recommendation), for which a probabilistic "virtual sample" was constructed of user behaviors to improve the coverage and accuracy of the items inputted into the deep model and extend the scope of multi-order extension information
(3) Multi-dimensional side-information (first-level categories, sub-categories, stores, brands, materials, purchasing levels, etc.) was embedded in item semantics through the shared-embedding plus pooling structure.
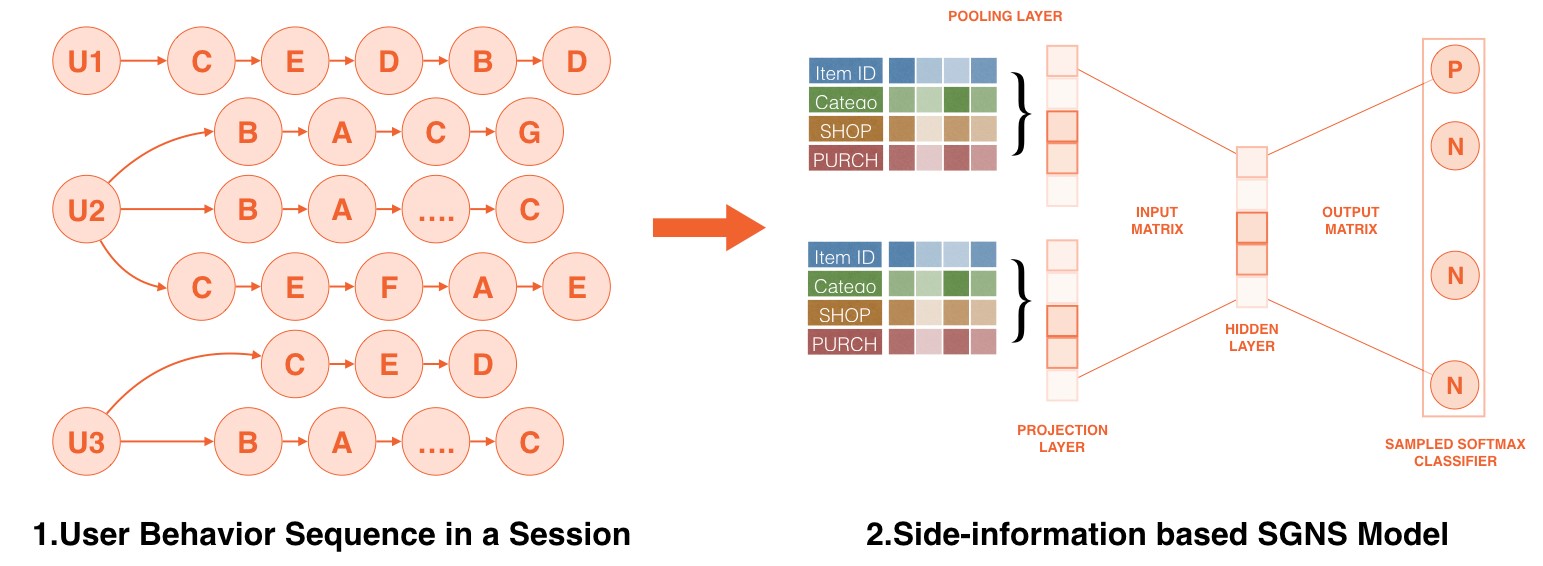
Sequence + Side information model structure
- For behavior sequences, there are two key points worth noting in practice when preparing behavior sequence data: (1) Choosing the time window for the behavior sequence; and (2) Filtering the users’ behavior noise and abnormal clicks based on the length of stay and the dissimilarity of categories selected.
- A new transition rate connection graph was defined to overcome hotspot issues in the real user session behaviors. The transition rate was calculated using each node as a center to compute the connection frequency and behavior co-occurrence frequency of the diffusing sub-nodes, and construct multi-order virtual samples on the hundreds of billions level based on deep walk.
- The side-information improves header precision of I2I results, with items from the same shop and the same brand ranking higher in the list, and also solving issues of cold start and fewer-behavior items.
The Final S³ Model
The side-information and behavior sequence substantially improved the accuracy of the model. However, the challenges posed by the overly wide embedding parameter space and the multitude of training samples (both at the hundreds of billions level) of all the items on the internet remained. In order to tackle this, the overall network was divided into several sub-graphs, with graph embedding training in each, and also with parallel training for different sub-graphs to shorten the training iteration period.
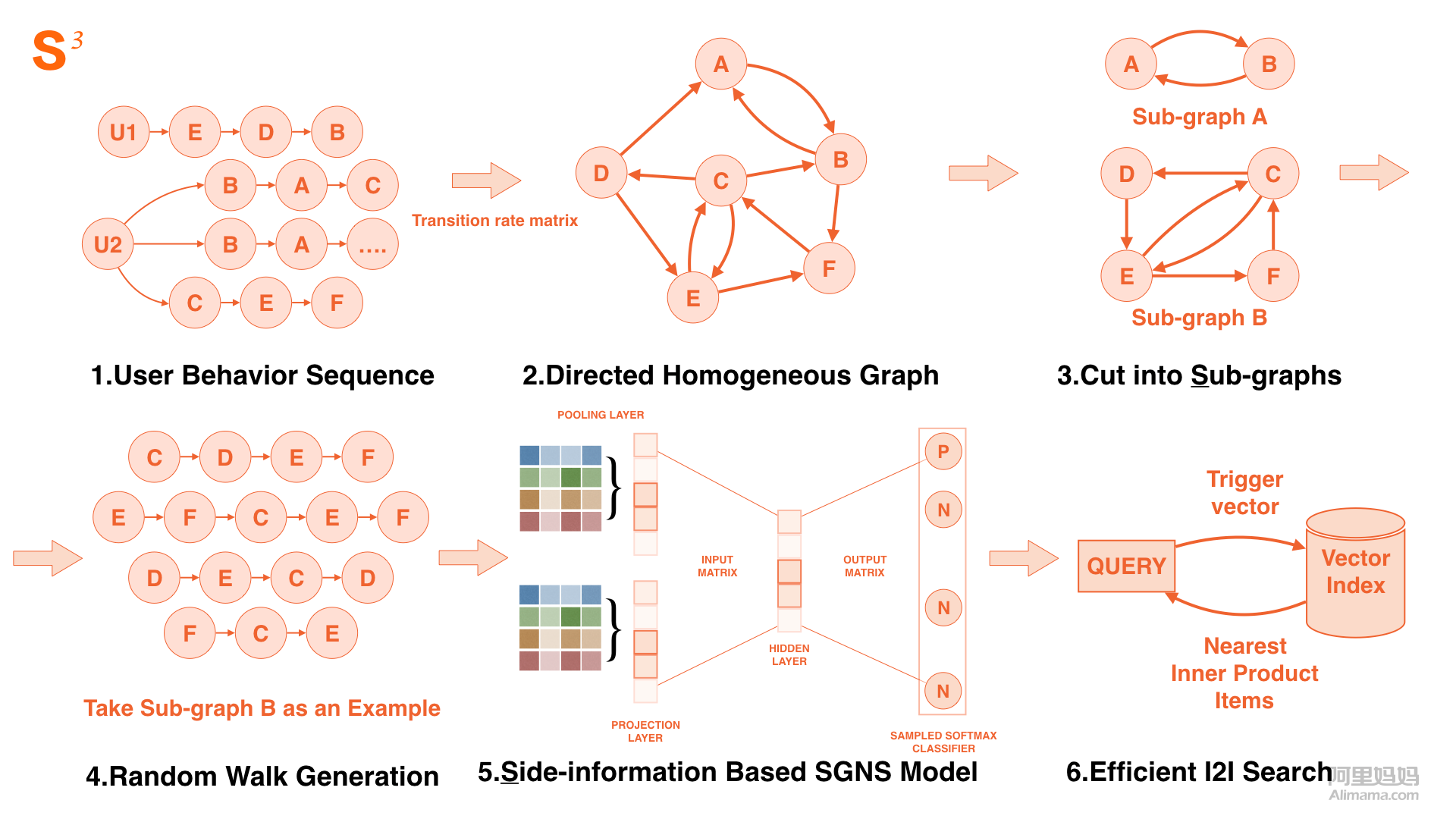
Final S³ model network structure
In the final recall link of I2I calculation, a query index was constructed for the embedding results. Based on the GPU clusters, a nearest inner product search was performed in batches to search the vector of item embedding.
Compared to the classic co-occurrence-based I2I algorithm, the final version enabled overall richer recalls and fewer bad cases. Below is an example of items recalled over the item pool on the homepage, where the three columns (left to right) represent the original items, Swing recalls and graph embedding recalls respectively.

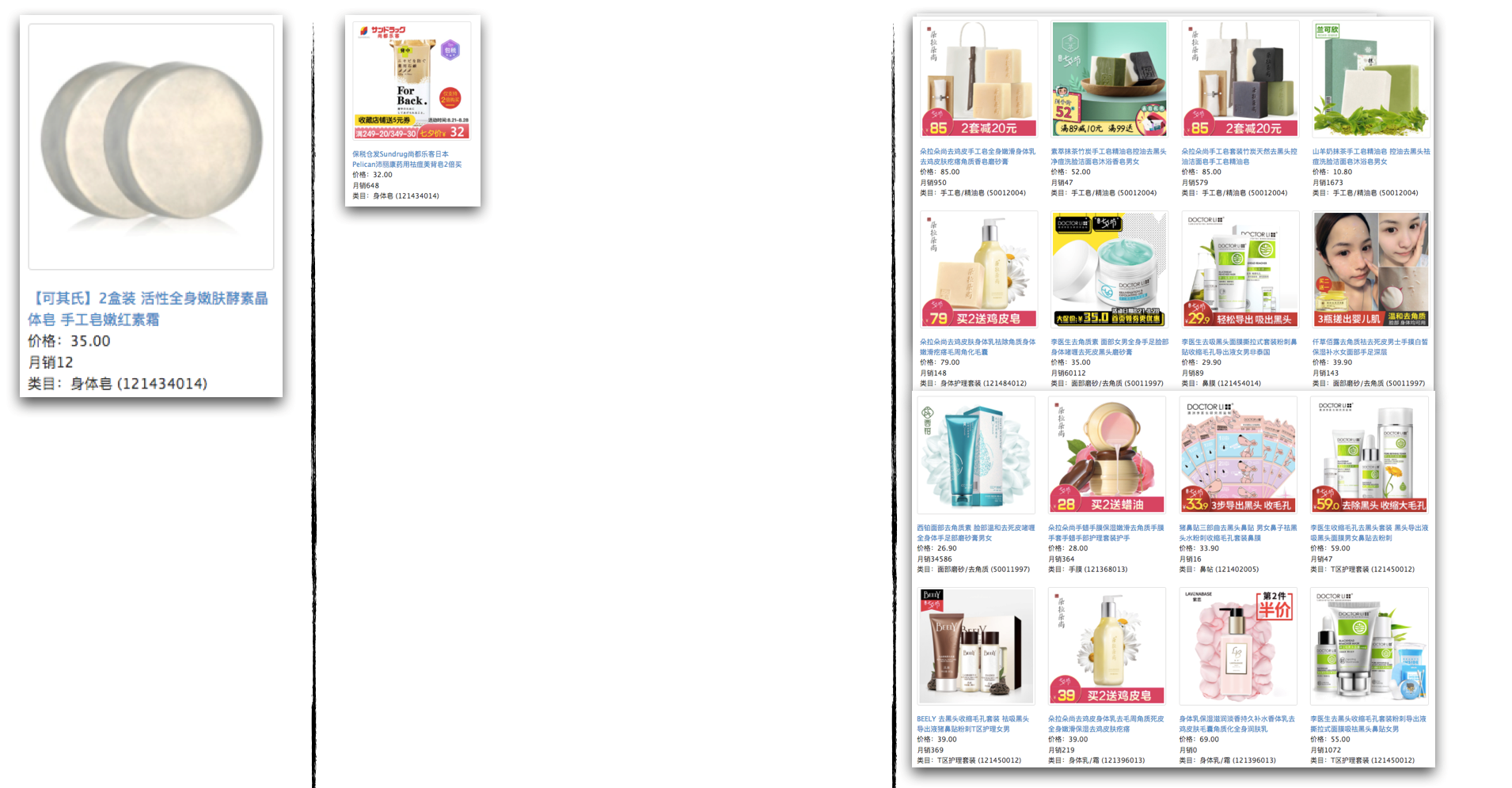
Recalled items on the homepage item pool
The following figure offers a more intuitive explanation for the high-dimensional embedding vector. An item in the sports footwear category is randomly selected for embedding vector dimensional reduction. Different colors represent different sub-categories, and each dot represents a coordinate of an item after dimensional reduction. We can clearly see that the embedding vectors of items in the same category are grouped together, indicating correct operation of graph embedding vectors.
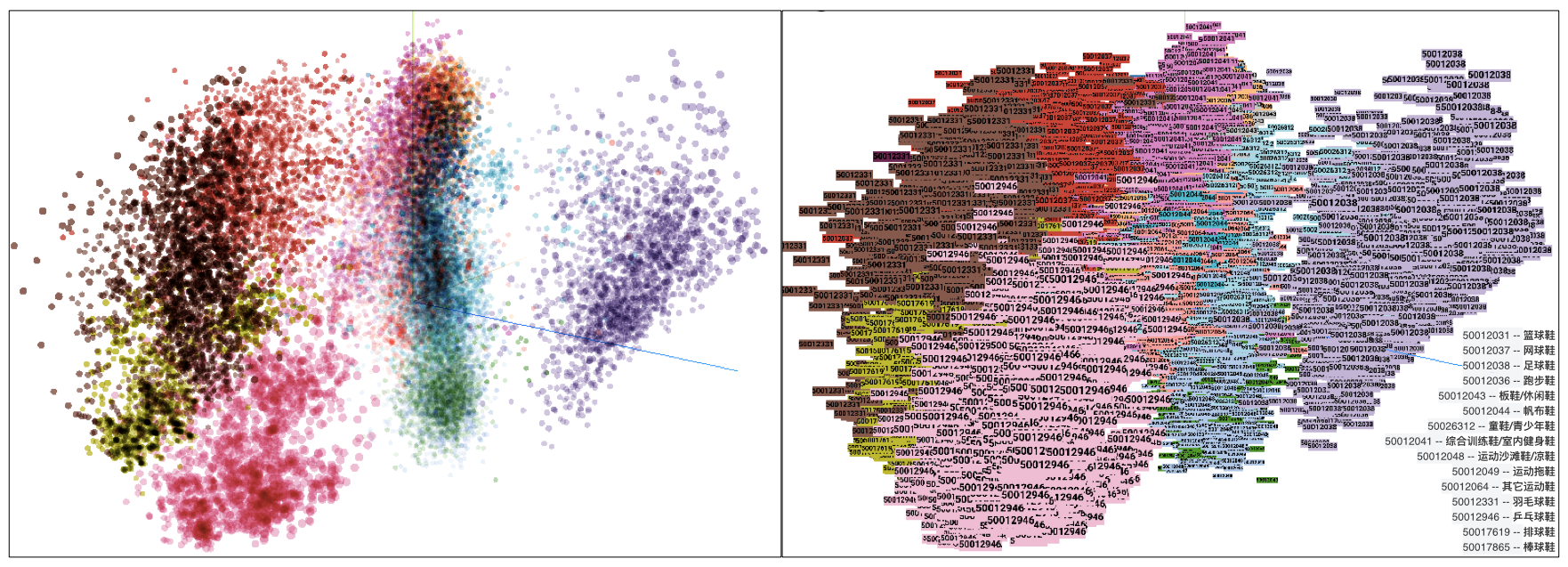
High- dimensional embedding vector
XTF-based Deep Ranking Model
Introduction to XTensorflow
Several homepage scenarios were managed, with the largest traffic distribution attributed to the Taobao mobile app, for the 2017 Double 11 Global Shopping Festival. Those scenarios have features including high traffic, more business rules and frequent business changes. Needing a stable, fast-iterating and real-time machine learning platform to support our training model and online scoring, one was co-constructed with the engineering team. Based on Porsche Blink's distributed training system and online servicing platform, the team members have developed various ranking models which achieve good results in the corresponding business scenarios. This platform was named XTensorflow (XTF).
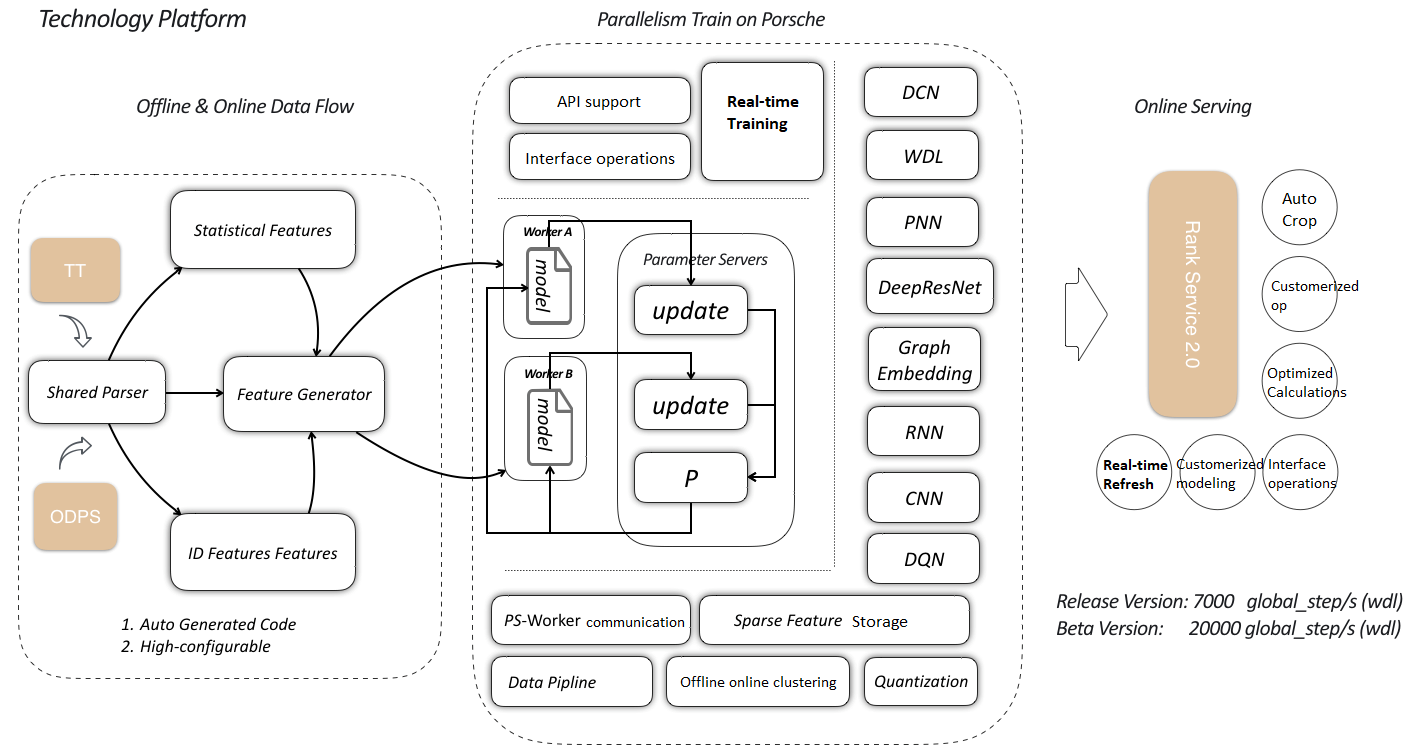
Outline of the XTensorflow (XTF) platform
The WDL deep model was widely used in various scenarios on the XTF platform. Furthermore, deeper models such as DCN and Deep ResNet have been implemented to achieve better results than the original WDL model.
Deep ResNet Applications in AIOplus Scenarios
When it comes to use of deep learning in recommendations, enhancing learning generalization by deepening the network when user item data and corresponding parameters are expanded is fairly standard. However, blind deepening of the network also causes several issues, notably parameter explosion, gradient disappearance, and over-fitting. The success of ResNet in the field of image recognition solved serious gradient disappearance in deeper networks. Testing on the deep side of WDL was started, observing how the increase of network derivatives and hidden-layer nodes worsened the training effect and performance of ordinary NN networks, leading us to supplement WDL with Deep ResNet.
The diagram of the basic principle is as follows:

Diagram showing the basic principles of the WDL-supplemented Deep ResNet
The original input layer containing embedding vectors of real-value and ID-category features was docked into a 10-layer ResNet, and the final loss was defined using logloss. The real-time Deep ResNet model was trained based on rapid user behavior changes in Double 11 scenarios and the variability of the AIOplus block activity materials (for example, where the operations team would the materials in real-time according to BI data), and was tested during the Double 11 warm-up promotions and the actual sales day.
DCN (Deep & Cross Network) Applications in Campaign Portal Personalization
By embedding sparse features along with a multi-layer full-connection Relu layer, DDN could automatically perform feature crossovers for high-order nonlinear learning. However, this crossover was recessive, prone to over-generalization, and difficult to monitor and manage. To amend this, the WDL model introduced a wide side that displayed interpretable feature crossover memory information to ensure model precision. However, this involved a great deal of feature engineering, and could only learn shallow two-order cross-product information. DCN introduced a cross network feature which controlled the number of feature crossover orders through network layers, and with fewer parameters for higher-order feature crossover than DNN. The definition for cross layer was simple: ,
![]()
and this design was more like ResNet with the l+1 layer's mapping function f actually fitting the residual ;
![]()
and the cross network eventually performed joint learning together with the deep network.
The complete network structure is shown below:
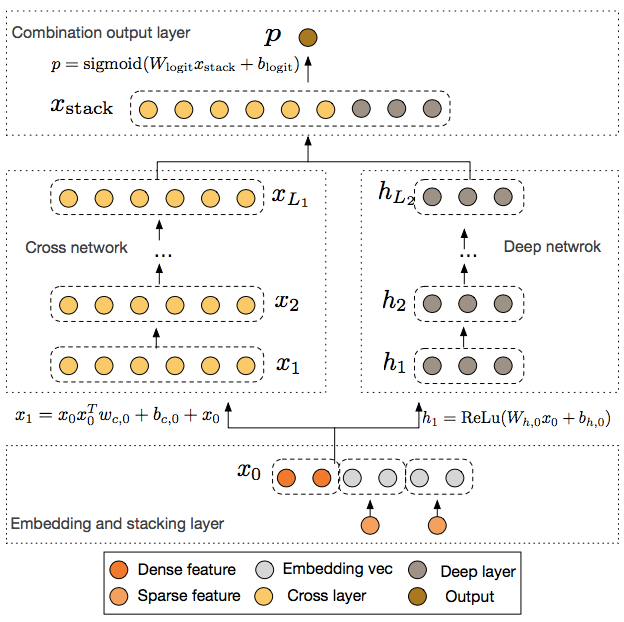
Complete DCN network structure
On the Double 11 Global Shopping Festival, the campaign portal scenario had fewer display slots, relatively sufficient recalls, and higher Top N precision requirements, resulting in the use of the DCN model to improve the accuracy of CTR prediction using high-order feature crossover. At the same time, since the modules displayed in the portal changed frequently, item granularity was chosen (rather than material content granularity) with higher requirements for the model’s generalization capability. As a result, a deeper DNN network was used to improve model generalization. As one of the major traffic-guiding scenarios, sufficient data had been created to learn the model, and in the final version implemented online, 3 cross layers and 10 deep layers was set up in the ResNet structure. In order to adapt to the changes of scenarios, a large amount of log cleaning was conducted. Compared with a pure real-time sample stream, an hourly-level sample stream was found to be more convenient for complicated sample cleanup. Therefore, during the tuning stage, we selected incremental hourly-level training, then switching to a real-time model.
Union-structured Deep Model
After Google’s proposal of Wide & Deep models, the high-dimensional framework of feature extracting (generalization), based on the deep side, and the display of feature crossing (memorization) model, based on the wide side, underwent various upgrades. Several classic models were organized and implemented, including WDL, PNN, DeepFM, NeuralFM, DCN and DeepResNet, all of which were based on the TF Estimator framework and encapsulated as model_fn with highly configurable feature processing and model training. At the same time, based on this long-term development in deep models, a union-structured deep model was proposed to meet a variety of business scenario requirements.
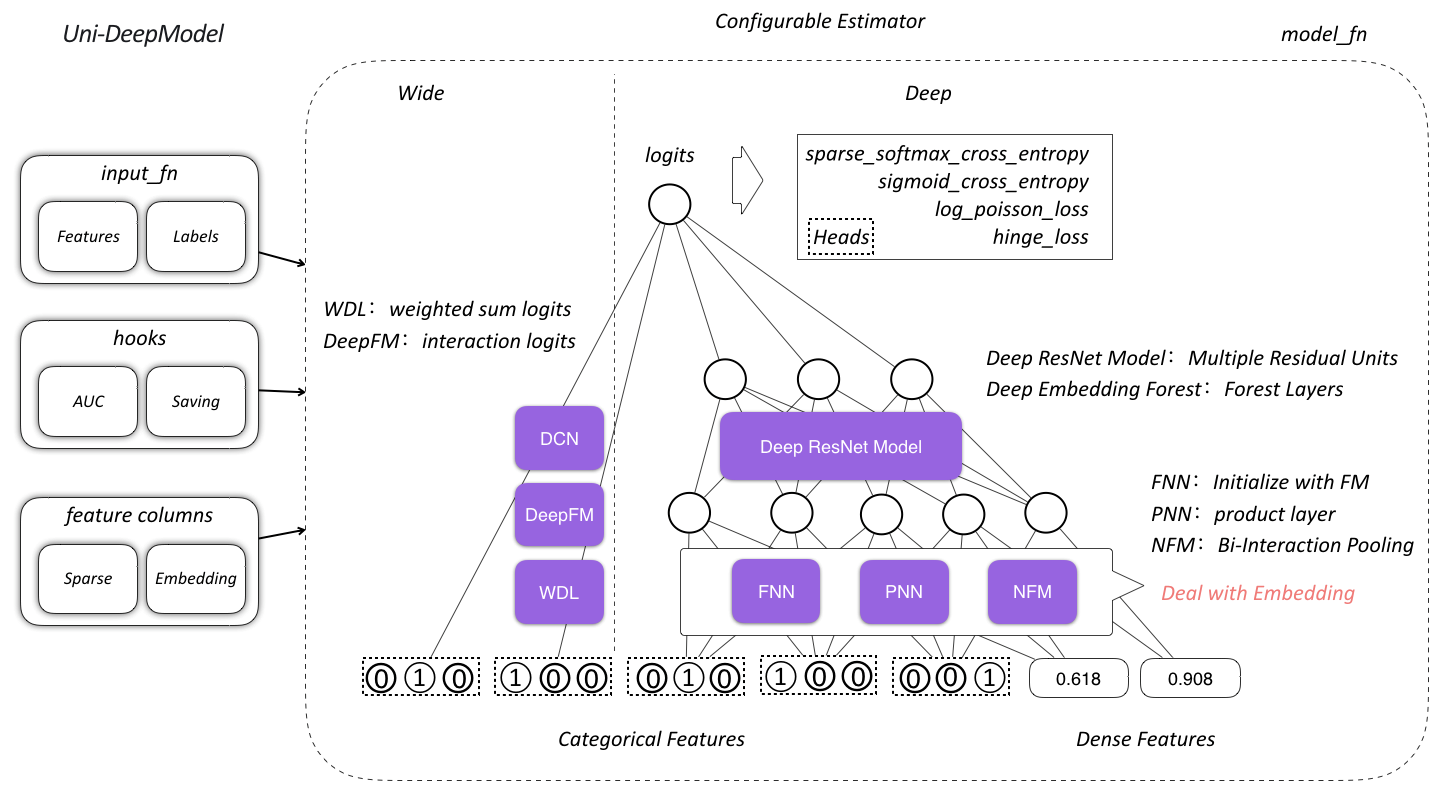
Proposed union-structured deep model
(Original article by Huang Pipei)
Alibaba Tech
First hand, detailed, and in-depth information about Alibaba’s latest technology → Search “Alibaba Tech” on Facebook
www.facebook.com/AlibabaTechnology
References
[1] DeepWalk: online learning of social representations. Bryan Perozzi, Rami Al-Rfou, Steven Skiena. Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining,2014.
[2] node2vec: Scalable Feature Learning for Networks. A. Grover, J. Leskovec. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2016.
[3] LINE: Large-scale Information Network Embedding. Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, Qiaozhu Mei. Proceedings of the 24th International Conference on World Wide Web, 2015.
[4] entity2rec: Learning User-Item Relatedness from Knowledge Graphs for Top-N Item Recommendation. Enrico Palumbo, Giuseppe Rizzo, Raphaël Troncy. Proceedings of the Eleventh ACM Conference on Recommender Systems, 2017.
[5] Discriminative Embeddings of Latent Variable Models for Structured Data, H. Dai, B. Dai and L. Song. International Conference on Machine Learning (ICML). 2016.
[6] Deep Coevolutionary Network: Embedding User and Item Features for Recommendation. H Dai, Y Wang, R Trivedi, L Song. Recsys Workshop on Deep Learning for Recommendation Systems. 2017.
[7] Predictive Collaborative Filtering with Side Information. Feipeng Zhao and Min Xiao and Yuhong Guo. International Joint Conference on Artificial Intelligence(IJCAI),2016.
[8] ICE: Item Concept Embedding via Textual Information. Chuan-Ju Wang, Ting-Hsiang Wang, Hsiu-Wei Yang, Bo-Sin Chang, Ming-Feng Tsai. Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2017.
[9] Distributed representations of words and phrases and their compositionality. Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean. Proceedings of the 26th International Conference on Neural Information Processing Systems, 2013.
[10] Meta-Graph Based Recommendation Fusion over Heterogeneous Information Networks. Huan Zhao, Quanming Yao, Jianda Li, Yangqiu Song, Dik Lun Lee. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2017.
. . .
Alibaba Tech
First hand, detailed, and in-depth information about Alibaba’s latest technology → Search “Alibaba Tech” on Facebook
