- Shopping With Your Camera: Visual Image Search Meets E-Commerce at Alibaba
This article is part of the Academic Alibaba series and is taken from the paper entitled “Visual Search at Alibaba” by Yanhao Zhang, Pan Pan, Yun Zheng, Kang Zhao, Yingya Zhang, Xiaofeng Ren, and Rong Jin, accepted by KDD 2018. The full paper can be read here.
From search engines to social media, the prevalence of online photos has increased exponentially in recent years. It’s not surprising that visual image search, also known as "content-based image retrieval", has also increased in popularity. Alibaba’s tech team brought this concept to an area where a good photo can make the difference between success and failure: online shopping.
Collaborating with the Machine Intelligence Technology Lab, Alibaba developed Pailitao, an application that applies the principles of visual image search to e-commerce, allowing users to search for items by taking a photo of the query object. At the push of a button, Pailitao automatically returns visually similar items on Taobao. This puts virtually any item at customers’ fingertips, whether encountered on the street or on social media platforms like Facebook and Instagram.
If you think this sounds like a useful feature, there are millions of others who would agree. Pailitao was an instant hit upon its launch in 2014, and had amassed a userbase of 17 million daily active users (DAU) by 2017. Usage peaked during that year’s Double 11 Global Shopping Festival—Alibaba’s annual shopping extravaganza in China—where the DAU count rose to over 30 million.
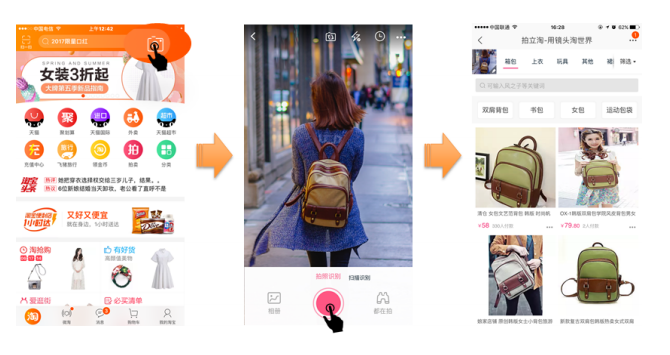 With Pailitao, an item seen on one’s morning commute can end up in one’s shopping cart with a few easy clicks
With Pailitao, an item seen on one’s morning commute can end up in one’s shopping cart with a few easy clicks
Developing Pailitao
While there has been a good deal of research into visual image search, researchers faced a set of unique challenges when developing Pailitao.
Unlike carefully staged inventory photos on e-commerce sites, user queries on Pailitao are taken from real life. Query images are often of a low quality and include busy background features that can complicate object localization. Additionally, most visual search solutions do not operate at Alibaba’s scale. With Alibaba’s large image collection with many fine-grained categories, visual image search technology requires a massive data architecture, and maintaining training data for deep models can be very expensive.
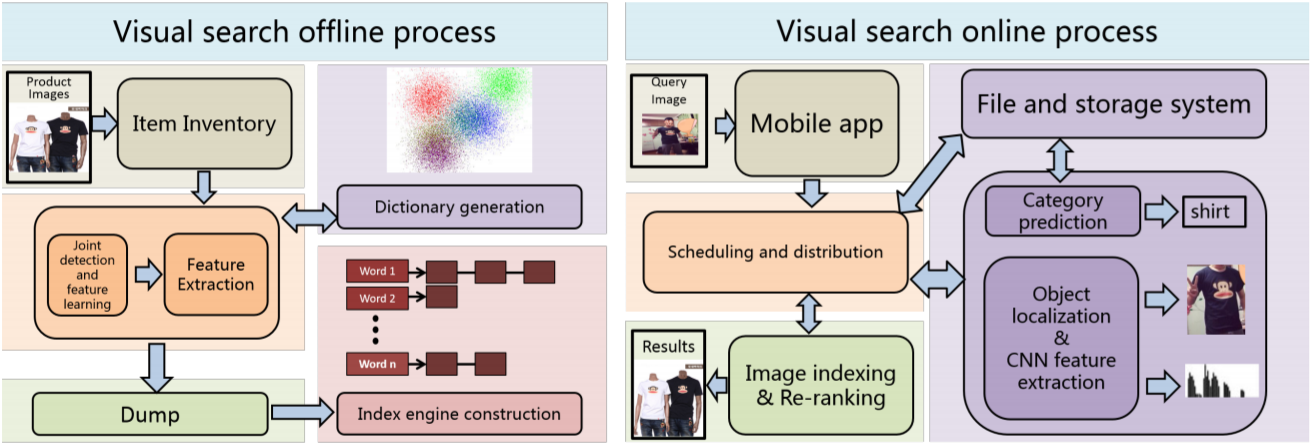 A diagram of Pailitao’s visual search architecture
A diagram of Pailitao’s visual search architecture
With these practical challenges in mind, researchers proposed a scalable and efficient visual search system. They introduced an effective category prediction method that uses a model and search-based fusion to reduce the search space. This allows for better scalability and achieves better performance for confusion categories and domain restrictions when compared to traditional methods.
Researchers also proposed a deep convolutional neural network (CNN) model with branches for joint detection and feature learning. This model is weakly supervised, minimizing the expense of human-labeled data. The model simultaneously discovers the detection mask and exact discriminative features without background interference. Researchers then instated a retrieval process that uses a binary indexing engine and re-ranking to train the model and improve customer engagement.
Combined, these features form a powerful large-scale indexing and retrieval technology that allows for responses in a matter of milliseconds, as well as lossless recall.
Far from a Photo Finish
Researchers conducted extensive experiments to evaluate the performance of each module in the system, collecting 150 thousand highest-recall images along with the identical item labels of retrieved results. From there, the Pailitao model and several other visual image solutions were tested on category prediction, search relevance, object localization, and indexing/reranking.
In each experiment, the Pailitao modules were competitive with or outperformed competing state-of-the-art networks. This data validates the effectiveness of the end-to-end architecture of Pailitao to serve its millions of daily active users. Moving forward, researchers hope to incorporate this visual search technology into more commercial applications.

The full paper can be read here.
--------------
Alibaba Tech
First hand and in-depth information about Alibaba’s latest technology → Facebook: “Alibaba Tech”. Twitter: “AlibabaTech”.
