- 含代码 | 支付宝如何优化移动端深度学习引擎?

阿里妹导读:移动端深度学习在增强体验实时性、降低云端计算负载、保护用户隐私等方面具有天然的优势,在图像、语音、安全等领域具有越来越广泛的业务场景。考虑到移动端资源的限制,深度学习引擎的落地面临着性能、机型覆盖、SDK尺寸、内存使用、模型尺寸等多个方面的严峻挑战。本文介绍如何从模型压缩和引擎实现两个方面的联合优化,应对上述挑战,最终实现技术落地,希望对大家有所启发。
1.背景
由于移动端资源的限制,大部分深度学习引擎都部署在云端,移动设备获取到输入数据,经过简单的加工,发送给云端,云端服务器经过深度神经网络推断运算,得到结果并反馈给移动端,完成整个过程。
显而易见,这种交互方式有很多弊端,比如依赖网络,流量过大,延迟太长,更重要的是,云端服务器必须有足够大的数据吞吐能力,如果移动端请求量太大,超过负荷,容易导致服务器宕机,从而使所有移动端任务都失效。其实,现有的移动设备已经逐渐从以前的单核32位到多核64位过渡,计算能力和存储能力有了很大的提升,将深度学习引擎部署到移动端已经成为一个必然趋势。
然而,成功将DL引擎部署到移动端并非易事。运行速度,包大小,内存占用,机型覆盖,甚至功耗都是必须逾越的障碍。支付宝移动端深度学习引擎xNN是这方面的佼佼者,本文将回顾xNN移动端DL优化的方法和技术。
2.运行速度
大部分移动端处理器都是基于ARM架构,移动端完成深度神经网络推断的任务,基于CPU的方案是最基础的,也是最可靠的;基于GPU的方案存在兼容性/数据同步/overhead过高/接口不满足等问题;DSP的方案也会存在兼容性的问题; 最近,很多手机芯片厂商开始构建AI协处理器(各种TPU/APU/NPU),但离应用还需要一定的时间。下面我们重点介绍一下在ARM平台的优化技术。做优化有三部曲,如下:
第一部:充分评估的优化目标。如果算法原型太复杂了,花再多精力优化也是徒劳。针对DL业务,务必让模型充分精简,直到你觉得差不多了才开始下手,不然的话,嘿嘿。
第二部:确认运算热点。这离不开一些timing profile工具,如XCODE instrument, GPROF, ATRACE, DS-5等,熟练地运用工具,可以事半功倍。
第三部:贴身肉搏。下面有利器若干。
2.1.基于C/C++的基本优化
编译器很牛逼,GCC/CLANG都有运行速度的优化选项,打开这些选项大部分情况下都会帮你的程序速度提升不少,虽然这还远远不够,但聊胜于无。
书写高效的C代码。循环展开,内联,分支优先,避免除法,查表等等优化小技巧一定要滚瓜烂熟,信手拈来。本文将不再赘述这些基本技巧。
必须学会看得懂汇编,即便你不写,也要知道编译器编译出来的汇编代码的效率如何。这样你可以通过调整C/C++代码,让编译器生成你需要的代码。否则,一切浮于表面。
2.2.缓存友好
基于CPU内存子系统的优化工作很大部分都是在想如何高效地利用缓存(cache),尤其是图像视频处理这种大量数据交换的场景。几十年前,我们的老前辈就发明了主存,多级缓存, 寄存器用来弥补存储器与计算单元的性能差异,直到今天这个问题还没有解决(或许一直都不会解决,存储器和计算单元的设计思路是不一样的,高速ram的成本肯定是高的)。存储层次如下图,原理很简单,你想跑得快,只能背得少,你想跑得快,还想装的多,那就要多掏钱买个车。
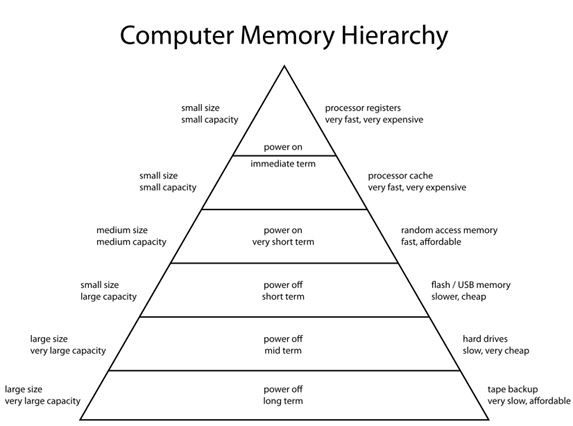
CPU-内存 子系统工作起来后,如果寄存器没数了,通过指令从L1 cache拿,L1没数了(Cachemiss),从L2拿,Cache都没有数据了,从主存拿,从主存拿的话, 也要分时间和位置,主存(dram/DDR)不同时刻不同位置访问的效率都是不同的。这里分享几个准则:
少用内存
尽量复用内存,不要随便地申请一大块内存。访问一大块内存意味着cache miss、TLB miss、dram切bank的概率都会增大,效率自然就降低。小块的内存反复使用,可以让CPU更加持久地运作,CPU运作占比越高,程序效率越高。要知道,一次cache miss导致的访问主存,在复杂应用下,可能有几十甚至上百个cycle的stall.
连续访问
数据访问一般都遵循局部性原理,位置相近的内存被重复使用的概率更高, cache的替换规则也大多给基于这个原理来设计,跳跃的访问内存会打破这个规则,造成访问效率的低下。
对齐访问
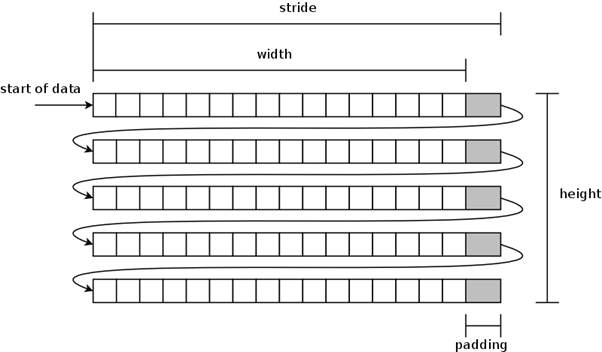
主存和缓存的最小数据交换单元是cache line, 所以访问内存的地址最好是按照cache line的大小进行,这样可以保证最高效的数据访问。比如某台机器cache line大小为64Bytes,申请一个128Byte的内存区域,将它的开始地址放在非64Byte对齐的位置,如0x80000020,那么访问这128Byte需要3条cacheline的访问, 若放在0x80000040, 则只需要2条cache line, 一般通过多申请一点点内存,来避免这种不对齐,比如用posix_mem_align() 函数;更近一步,为了对齐访问,有时需要对图像的边界做一些padding的,比如 224x224的图片,我们可能会存储在256x224的内存地址中,保证在随机访问某一行时,地址处于对齐的位置。如:
合并访问
如果反复的读写一段内存进行运算,效率上肯定不如“一次读取-多次运算-一次写入”来的更高效。比如,DL模型中,一般CONV层后面跟着RELU,BIAS层,本着内存访问能省则省的原则,通过提前分析网络的结构,可以将CONV层和bias合并,甚至将CONV+BIAS+RELU合并在一起进行运算,可以获得很好的gain. 比如:
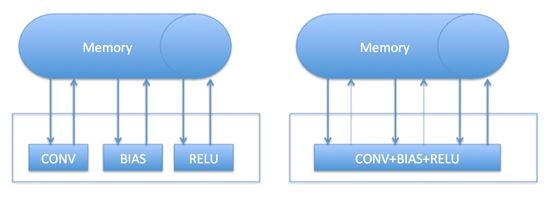
经过合并后,原来对memory的三读三写,变成了三读一写,速度杠杠的。
显式对齐数据加载
在ARM汇编中,可以显式的通知CPU,加载的地址是一个对齐得较好的地址。比如

其中,“:128” 即是通知CPU, R1存放的地址是一个128bit对齐的地址,此时,CPU在向内存发出数据请求时,可以发出更高效的信号。如果R1不是128bit对齐的,执行这样的指令会得到一个地址异常,也就是LINUX中常见的 bus error。怎么保证R1是128bit对齐? 程序员必须知道R1对应的数据结构,需要事先设计好地址偏移,保证该指令被正确执行。并不是所有case都可以满足这个要求。
缓存预取
请设想,如果CPU正热火朝天的做计算,这时我们在后台偷偷搬些后面会使用的数据到缓存,下次使用时CPU就不用再去等数据了,效率不是就变高了吗?是的。缓存预取可以做这个事情,如:preload [R1, #256], 可以让CPU在继续执行后面的指令,并开始在后台加载 $R1+256byte位置的数据到缓存中。
但是,preload是一条指令,当你发出这样的指令时,需要知道,至少一个cycle浪费掉了,然后再考虑你预加载进cache的数据,是不是马上就可以接着被CPU 采纳。不幸的是,在手机实时操作系统中,可能多达几十甚至上百个线程嗷嗷待哺,完全无法保证预取的这些数据会被马上用上,系统中有大把事件是会让你的线程找地方歇息的,这种情况下,你预取的数据非但不能用,还可能被其他线程从cache中踢出去,白白浪费了一次主存访问。但是梦想总是要有的,万一实现了呢,总要试试才知道效果吧!
类似的方法可能还能举出一些来,但宗旨只有一个,在做同样的事情的前提下,别让你的CPU经常停下来等数据。
2.3.多线程
手机核备竞赛前几年搞得如火如荼,最近慢慢冷下来了,但也说明多核在运算上还有很大的优势。当然,多核的使用,会导致CPU占比和功耗直线上升,但在可接受的条件下,多线程优化带来的性能提升是最可观的。多线程的实现方法推荐使用OPENMP,接口丰富,编程简洁,用起来并不难,但需要注意一些细节。
线程开销
OPENMP会自动为循环分配线程,但并非所有循环都适合做多线程优化,如果每次循环只做了非常少的事情,那么使用多线程会得不尝失。线程的创建和切换会消耗一定的系统资源,线程调度有一定的规律,操作系统在没有高优先事件触发的情况下(中断,异常,信号量), 调度周期都在毫秒级别,如果每次线程执行时间没有达到一定的量,多线程的效果就会大打折扣。实际运用中,可以通过 #pragma omp parallel for if (cond) 语句来判断runtime过程中是否要启用多线程。
动态调度
默认情况,OPENMP采用静态调度机制,即将循环的次数平均分配给各个线程,不关心各个线程的执行快慢。如果某次循环运行比较慢或者循环次数不能平均分配时,容易出现负载不均衡的情况,这时就必须有动态调度的机制,动态调度可以根据线程的运行快慢,决定是否“互相帮助”。 OPENMP可以采用schedule(dynamic)来达到动态调度的效果。

同时需要说明的是,某些机型对于OPENMP的支持并不好,或者说线程的开销过大,这时,可能需要手动调整线程的负载和并行的方式。这些细节需要通过反复的实验来微调。
2.4.稀疏化
深度神经网络是个超级黑盒,人们把神经突触的权重找出来了,让整个网络可以完成特定的任务,但却不知道每根突触的作用是啥。实际上,其决定作用的很可能就只是那“几根筋”。我们的实验结果也是如此,大量的权重数据都可以是0,而整个输出精度相差无几。当发现网络中有50%甚至80%的数据为0时,那么针对稀疏的卷积和矩阵优化就显得非常重要了。
稀疏优化的重点是设计合适的索引方案和数据存放方式,如下图。
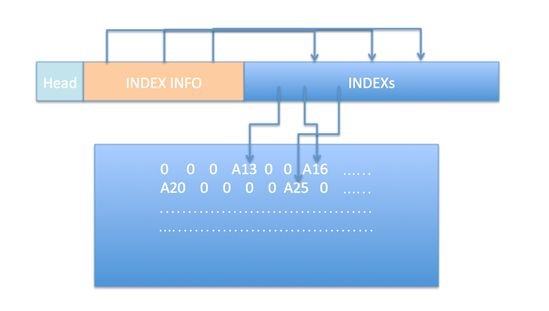
稀疏方案的应用,依赖不同的运算结构,如针对1x1卷积的优化,数据组织方法和3x3卷积就可能存在不同,不同的稀疏程度,得到的提升效果也是不同,需要不断地尝试各种方案和参数。
2.5.定点化
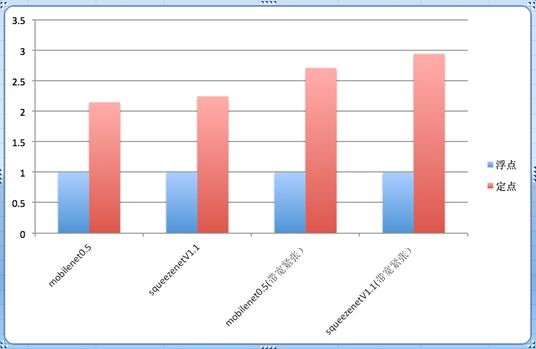
大部分深度神经网络推断引擎,都需要用浮点精度来得到更精确的结果,这样paper上的数据才好看。但实际上,有些DL应用并不需要这么高的精度,即便是单精度浮点,也存在很大的冗余运算。以Tensor的1x1的卷积为例子,实际就是一个乘累加的过程,若使用单精度浮点存放数据,每个元素需要4个字节,而如果将数据量化到8bit, 只需要1个字节,节省3/4的内存访问量,这意味着在带宽紧张的状态下,性能提升会更加明显。下图体现了不同场景下定点化的性能提升收益(倍数)。
2.6.NEON及汇编
NEON 是针对高级媒体和信号处理应用程序以及嵌入式处理器的 64/128 位混合 SIMD 技术。它是作为 ARM内核的一部分实现的,但有自己的执行管道和寄存器组,该寄存器组不同于ARM 核心寄存器组。NEON 支持整数、定点和单精度浮点 SIMD 运算。经过良好设计的NEON代码,理论上可以比普通C语言版本快2-8倍。
NEON指令集分为ARMV7版本和ARMV8版本,寄存器个数和格式略有不同。写NEON指令有两种方式,一种是NEON Intrinsic, 一种是NEON Inline Assembly(内联汇编)。
本文主要是分享一些用Neon/汇编优化的经验,学习具体neon/汇编写法可以参考:
https://community.arm.com/android-community/b/android/posts/arm-neon-programming-quick-reference
2.6.1.NEON Intrinsic vs Neon 内联汇编
大部分情况下采用NEON Intrinsic编程就够用了,NEON Intrinsic的好处也是非常明显的,首先,在armv7,armv8平台都可以跑,其次,代码简洁容易理解和维护,另外,编译器还会根据不同平台做代码重排;但是NEON intrinsic也有一些缺点,比如没有预取指令,分解Neon寄存器很麻烦,寄存器分配可能不高效,无法做显式的对齐加载,编译器可能会引进一些奇怪的指令,造成性能低下。
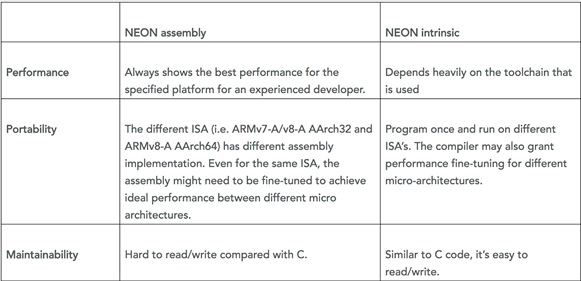
如果对某个模块的性能要求很高,编译器的输出不满足要求,这时候,就需要使用内联汇编;对于xNN中的核心模块卷积运算,都是通过内联汇编实现,性能比NEON Intrinsic提升10%左右。以下是ARM官方例子:
当然还有一种方式是采用纯汇编写程序,这不是所有人都能接受的。付出得多,收获也多,真正的高效的程序都是纯汇编的。相对编译器产生的代码,手工纯汇编的好处还是非常明显的,比如精简的栈内存,高效的寄存器利用,充分的流水线优化等等,有一种一切尽在掌握的快感。
但是,大部分情况下,用纯汇编写程序花去的精力,完全有机会在其它地方去弥补。所以这种方式适合追求极致的同学。
2.6.2.会写NEON/汇编很重要,构思好的实现方案更重要
NEON指令比较丰富,实现同一个功能有多种指令组合,除了理解指令的本身的作用之后,需要合理组织数据,使用更高效的指令来实现既定功能。
举个例子,实用实现单精度浮点矩阵乘法 sgemm中的 C = A * B + Bias,为了简单起见,假设矩阵的维度是2的幂。如 Dims(C) = 512x512, Dims(B) =512x512, Dims(B) = 512x512, Dims(Bias) = 512x512;
代码1 : C语言的写法是:
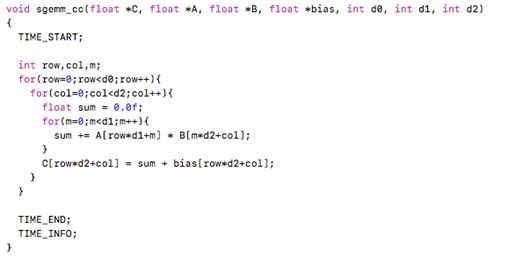
运行时间是: 1654689us (小米5 snapdragon 820,下同).
为了构造SIMD,我们将4个C的元素同时输出,如:
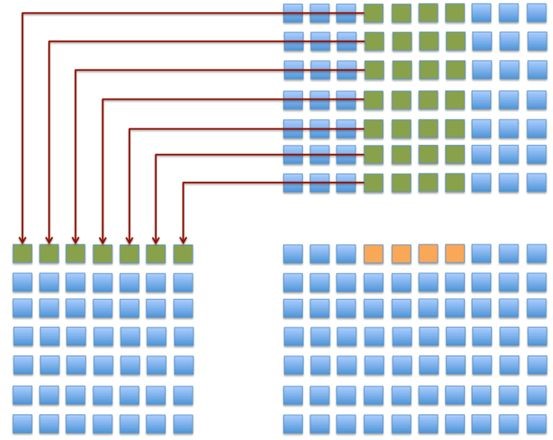
从而产生代码2,这是初步的NEON写法:

运行时间:633551us
考虑到数据的重复加载,可以多取四行,一次输出4x4的block, 这样可以省下接近3/4的数据读取,如
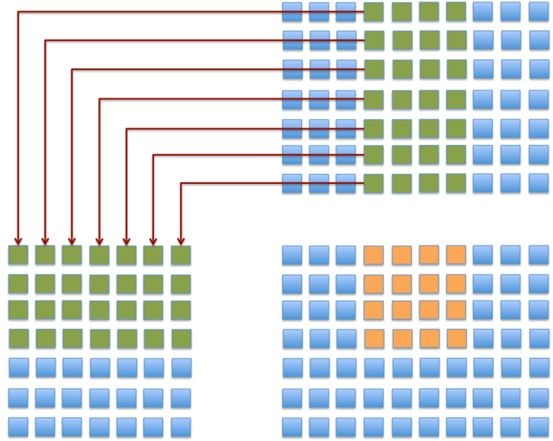
从而得到代码3:

运行时间:367165us
进一步,我们发现矩阵B的取数不连续,每次只取4个float, 远不到cache line (64Byte),相当于cache miss有3/4是有可能被优化掉的,存在很大的浪费,所以对B的数据做转置,转置的过程可以和实际代码结合,减少额外内存拷贝;同时,我们将Bias的作为sum的初始化值, 减少一次写操作。于是得到代码4:

运行时间是:60060us
最后,按4x4的block进行循环构造,然后用OPENMP进行多线程化,得到代码5:
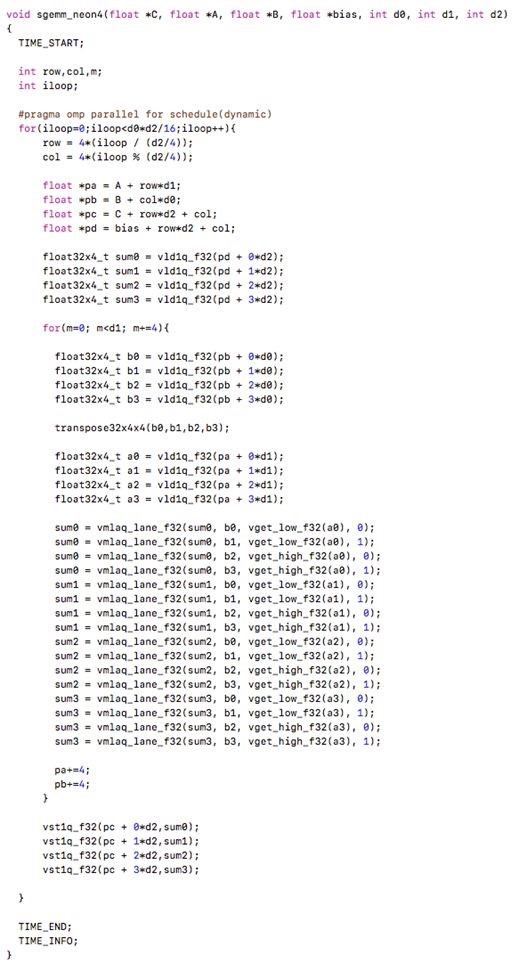
运行时间25178us
上面四种NEON写法的运行速度增益分别是:
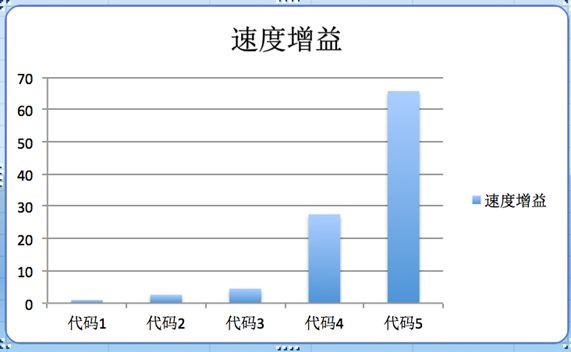
代码5肯定还不是优化的终点,通过数据重排,4x4的转置部分还可以省掉;cache的优化还可以更加细致;4x4的块是否是最优也有待论证;最后,还可以祭出汇编大杀器,性能还能再上一个台阶。
sgemm的优化版本还可以参考nnpack/eigen等开源库。实际代码中,需要处理各种维度的情况,代码远比上述要复杂。
3.包大小
移动端的资源紧张,不仅仅是指运算资源,app大小也是商用DL引擎一个重要指标,更小的包大小意味着更快的下载速度,更少的app下载流量。app大小的压缩包括很多方面,这里我们只针对库文件的大小精简,做一些经验分享。
3.1.编译优化
编译器有针对大小的编译选项,比如GCC的-Os, 相当于可以同时打开-O2的优化效果,同时精简生成目标文件的尺寸,生成目标代码后,链接成动态库的时候,可以通过strip命令,去掉多余的调试代码。这些是最基本的优化。针对IOS, 可以通过XCODE下面方法做精简:
-
BuildSettings->Optimization Level,XCODE默认设置为“Fastest ,Smallest”,保持默认即可
-
Build Settings->Linking->Dead Code Stripping 设置成 YES
-
Deployment Postprocessing 设置成YES
-
Strip Linked Product 设置成YES
-
工程的Enable C++ Exceptions和Enable Objective-C Exceptions选项都设置为NO。
-
symbols hidden by default选项设置为YES。
-
所有没有使用C++动态特性的lib库(搜索工程没有使用dynamic_cast关键字) Enable C++ Runtime Types 选项设置为NO。
上述配置,在IOS设置输出目标为release时,XCODE会帮你自动打开一部分配置。同样的,在Android NDK编译,在Application.mk中配置OPTIMIZE=release,NDK会帮你做绝大部分的优化工作。
针对资源紧张的嵌入式设备,ARM提供了thumb/thumb2精简指令集, 相当于,同样的指令,同时有 16bit 和32bit 两套指令,使用 -MThumb选项可以让编译器优先编译出16bit的指令,在执行时通过内置的译码器,将指令转换成32bit的指令,这样既可以精简代码,还可以保持原来32bit指令的性能。
针对动态库的发布,还可以通过Invisible Symbol的方式,将不需要的符号隐藏起来,省下目标库文件中符号表的表项,如果你的代码有大量的函数,这会是不小的提升,试试看,说不定有惊喜。具体写法是:

这样就ok了,简直是物美价廉!
3.2.代码精简
以上都是一些常规的缩小库大小的方法,实际上,针对DL模型的特性还可以进一步精简库大小,比如包括:
-
库依赖简化- 大部分开源引擎都会依赖C++ STL库,如Caffe/Tensorflow, 如果要做到极致的精简,需要将复杂的C++属性去掉,这样可以依赖更加紧凑的stl库,甚至不依赖stl.
-
功能裁剪 - 删除不常用的layer,删除不常用的代码分支,或者Layer组件化,用时加载,都可以减少基本库大小;
3.3.模型压缩
深度学习模型的size,小到几M,大到几百M,如果不做压缩,根本是不可想象的。模型中的大部分数据是神经网络的突触权重,存在有巨大的压缩空间。比如, 支付宝xNN团队提供的xqueeze工具,可以让深度学习模型压缩比例达到几十甚至一百倍。压缩技术包括神经元剪枝 (neuron pruning)、突触剪枝(synapse pruning)、量化 (quantization)、网络结构变换 (network transform)、自适应Huffman编码(adaptive Huffman)等等。具体实现可以参考一些主流的Paper。
4.内存精简
内存使用也需要精简,低端机型有可能只有1G甚至512M的内存空间,再复杂的应用场景下,经常会不够用。精简内存,可以一定程度上缓解内存不足引起的闪退;另一方面,使用更少的内存也有利于推断速度的提升;
具体到DL推断过程运行时存在很大的内存冗余,比如:
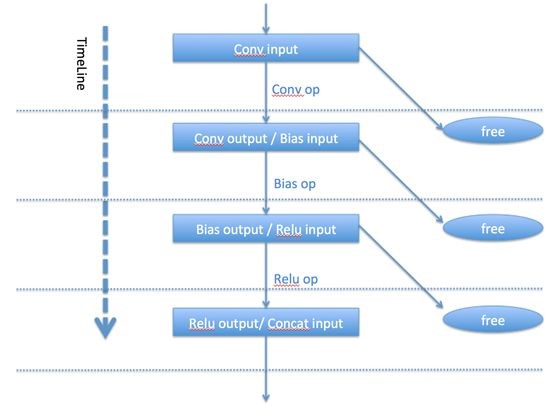
实际上,推断过程中,大部分输入层在做完运算后,可以被马上释放,所以完全存在复用内存的可能性。
支付宝xNN 设计了一种称为MPool的内存管理机制,结合深度学习推断的过程,MPool 通过分析网络结构,在内存充分复用的前提下,计算出最小的内存使用量,在开始推断前提前申请足够的内存。

MPool有如下几个优点:
-
避免推断过程中反复申请释放内存;
-
内存申请全部集中到初始化过程,避免推断过程中出现内存不足导致的推断失败,从而改善用户体验;
-
充分的复用可以提高的内存访问效率,对性能提升也有一定的帮助;
采用MPool结构的DL引擎,运行主流模型,内存占用降低达到75%以上。
5.兼容性与可靠性
商用软件,兼容性和可靠性是很重要的指标。举个例子,支付宝xNN在春节扫五福活动中,机型覆盖率达到98%以上,基本上只要是ARM based的手机,电池不要随便爆炸,就可以支持。然而兼容性和可靠性的提升,不比开发过程顺利多少,需要解决很多工程上的问题。
举几个例子:
为了在支付宝app中部署xNN,需要兼容app中的stl版本;
为了兼容旧版本的Android, 必须使用较旧一点的NDK版本和API, 否则会出现一些数学库的兼容性问题;
为了保证连续多次运行内存不泄漏,需要在不同android/ios版本的上做疲劳测试;
为了多任务并发,需要做互斥;
为了兼容受损的模型文件,需要做多层次的模型校验和兼容。
……
这样的例子还有很多。总结一句:出来混的,迟早要还的;代码中的任何瑕疵,最后总会被爆出来。
6.更多
基于CPU的实现方案,面对复杂场景/强实时性应用,还是力不从心的,毕竟CPU资源是有限的,永远都无法预测用户部署的模型的复杂度,也无法预测手机后台运行了多少程序;异构化也是重要的优化方向,采用DSP/GPU来做推断可以大大降低功耗,同时还可以提升推断速度,DSP/GPU方案面临的问题是兼容性比较差,每一个款手机都有可能不同,所以需要做大量的适配工作。
最后,模型安全也是需要考虑的方向,模型文件包含了用户的知识产权,对模型文件适当加密和隔离运行,可以有效地阻止模型被破解和盗取的风险。
