- Lost for Words: Speech Synthesis with Limited Data Using Linear Networks

Speaker-dependent acoustic models ensure that speech synthesis systems give accurate results. Given an adequate amount of training data from target speakers, speech synthesis systems are able to generate results similar to the target speaker. However, gaining enough data from target speakers is always a constraint.
Speaker adaptation can be used to obtain satisfactory target speaker voice fonts using only limited data. This approach is less labor-intensive than mass recording, manual transcribing and review, and ultimately reduces the cost of creating new voices.
To improve the stability of these adapted voices, the Alibaba tech team have investigated applying Linear Network (LN)–based speaker adaptation methods and Low-Rank Plus Diagonal decomposition (LRPD). A breakdown of these approaches is illustrated below.
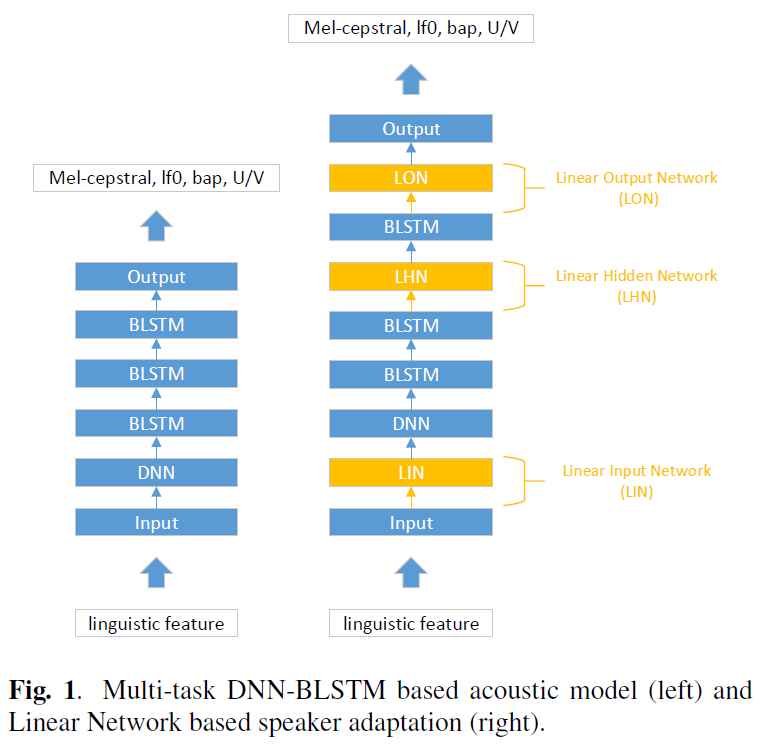
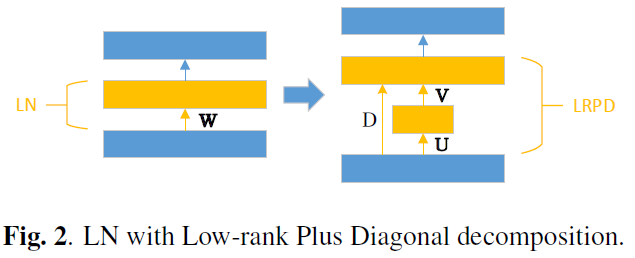
The effectiveness of these approaches was evaluated by conducting female to female, male to female, and female to male speaker adaptation. Results shown that using LN with LRPD decomposition is most effective when adaptation data is extremely limited. Moreover, using this method with a speaker adaptation model containing only 200 adaptation utterances achieved comparable quality to that of a speaker dependent model trained with 1,000 utterances in terms of naturalness and similarity to target speakers.

Read the full paper here.
. . .
Alibaba Tech
First hand, detailed, and in-depth information about Alibaba’s latest technology → Search “Alibaba Tech” on Facebook
