- An Ensemble Framework of Voice-based Emotion Recognition
This article is part of the Academic Alibaba series and is taken from the paper entitled “An Ensemble Framework of Voice-Based Emotion Recognition System for Films and TV Programs” by Fei Tao, Gang Liu, and Qingen Zhao, accepted by IEEE ICASSP 2018. The full paper can be read here.

The importance of emotion recognition is gaining more and more traction with improving user experience and the engagement of human-computer interfaces (HCI). Developing emotion recognition systems that are based on speech, as opposed to facial expressions, has practical application benefits due to low hardware requirements. However, these benefits are somewhat negated by real-world background noise impairing speech-based emotion recognition performance when the system is employed in practical applications.
To overcome these issues, researchers from the Alibaba tech team and The University of Texas at Dallas have developed an ensemble framework of speech-based emotion recognition that captures characteristics from audio from several aspects, including low-level utterance descriptors, high-level utterance representations, sequential acoustic frame features, and lexical information. By thoroughly capturing acoustic information in this way, the ensemble framework effectively overcomes background noise issues. A breakdown of the ensemble framework is illustrated below.
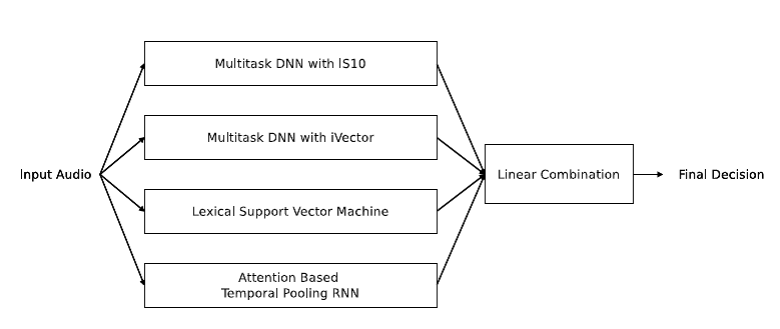
In order to evaluate this framework, the research team used movies and TV shows that have real-world sound profiles. The proposed ensemble framework outperformed state-of-the-art baselines that utilize deep learning. This achievement facilitates the employment of the emotion recognition system to practical applications.

Read the full paper here.
. . .
Alibaba Tech
First hand, detailed, and in-depth information about Alibaba’s latest technology → Search “Alibaba Tech” on Facebook
