- Alibaba Blink: Real-Time Computing for Big-Time Gains
How a new real-time computing framework made Double 11 2017 the largest real-time computing phenomenon in history

With the diverse ecosystem it presides over – now spanning e-commerce platforms Taobao and Tmall, advertisement platform Alimama, Ant Financial, Alipay, AliCloud, and Big Entertainment to name but a few – the data on Alibaba’s servers measures into the exabytes and is growing daily by petabyte proportions.
However, more impressive than the volume of Alibaba’s data are the ways in which the data is being used. This is especially true in moments when all eyes are on the company and expectations are running high, with shoppers, merchants and the media anticipating a dazzling application of its cutting-edge technologies. No moment quite matches the Double 11 Global Shopping Festival in this respect.
Enter real-time computing
Each Double 11, real-time computing is used to calculate the gross merchandise volume across Alibaba’s entire e-commerce operation in real time. The total is then displayed on a big screen and updated second by second.
 The Double 11 2017 big screen reported GMV in real-time
The Double 11 2017 big screen reported GMV in real-time
Although based on a simple principle, successful implementation of the GMV screen is still an impressive feat given the high requirements that the process entails in terms of speed, volume, accuracy and system availability.
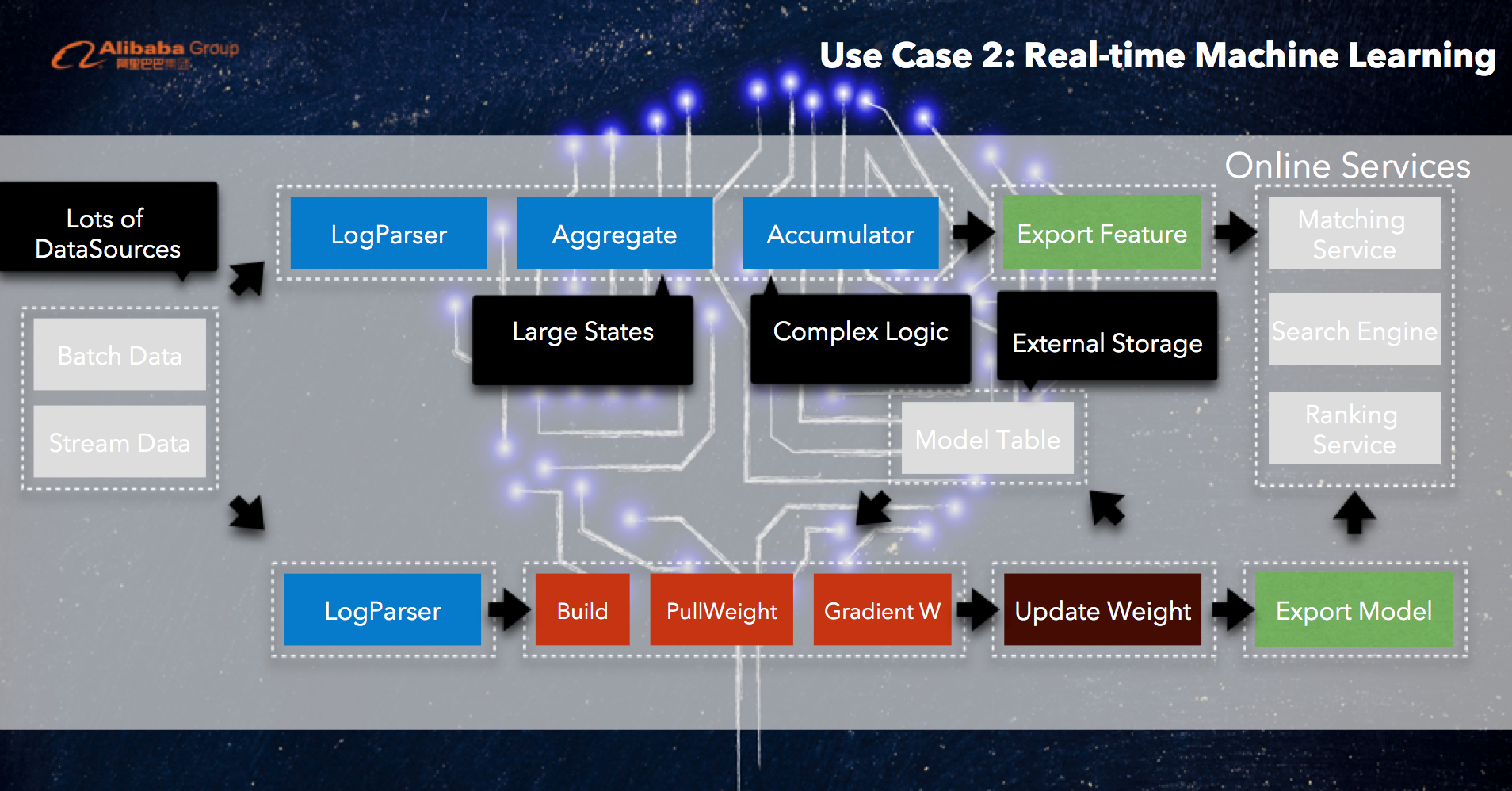
But even more formidable implementations of real-time computing lie behind the scenes at Alibaba that are highly complex both in principle and in practice. These include real-time machine learning and real-time A/B testing. Each poses unique demands on the real-time computing framework, from the complexity of the calculation logic to the sheer number of data sources involved.
To address these challenges, Alibaba has developed its own real-time computing framework. Using Apache’s open-source framework as a basis, Alibaba made crucial improvements to greatly boost Flink’s scalability, reliability, and performance. The resulting enterprise framework, Blink, has been a resounding success as the foundation for record-breaking achievements in real-time computing over the past year.
With Blink in the background calculating real-time GMV, and supporting machine learning to predict users’ preference and make proper recommendations to the customers in a real-time manner, Double 11 in 2017 marked the single largest concurrent computing phenomenon in history. At its peak, the framework processed 470 million events per second. This contributed to phenomenal earnings of 168.2 billion RMB in a single day.
What makes Blink such a powerful real-time computing framework? To start with, Flink was hand-picked for its strong core functionality. Flink was not without its limitations, however, and the Alibaba team introduced a host of modifications in the form of Blink runtime and Flink SQL to overcome these challenges.

From Flink to Blink
Among available computing frameworks, Apache Flink stands out for its ability to accurately yield a state for describing complex data sets – the kind Alibaba has oceans of – and for its unique Chandy-Lamport algorithm, well-suited to executing exactly-once semantics (required for high-accuracy computing). Flink did, however, have certain shortcomings, a problem Alibaba turned to adaptive innovation to address.
Unlike Alibaba, most companies using Flink generally does not seek to customize for storage, scheduling, and underlying optimization. Alibaba’s needs called for substantial alterations deserving separate mention from an open source project – namely Blink’s Runtime component.
Blink’s second component – Flink SQL – required no such renaming. Blink wants to keep the compatible API within the open source Apache Flink, and Blink developers at Alibaba were the major contributors to Flink SQL, including stream SQL semantics as well as many stream SQL functionalities. It features extensive updates for user convenience, with stream computing fully integrating the user, API, Blink, and Flink into the community, improving on native Flink’s low-level data stream API.
Blink Runtime: Key developments
Optimized cluster deployment
In tandem, Blink Runtime opens new possibilities for large-scale cluster deployment, owing to a reworking of the original framework for vastly improved scalability. Whereas Flink clusters featured only a single Job Master, and thus a bottlenecking problem when faced with many jobs, each job in the Blink framework has its own corresponding Master. For similar reasons, Blink also assigns each job to its own Task Manager, preventing the issue of Task Manager collapse prevalent with Flink – e.g. an unhandled exception in a single task takes down the entire worker process, thereby killing other perfectly fine running tasks.
Blink further optimizes the previous improvements by introducing a Resource Manager, capable of communicating with Job Masters and adjusting resources in real-time for optimal cluster deployment.
Incremental Checkpoint design
Real-time computation requires constant preservation of the state of computing at checkpoints. Flink’s checkpoint model was unsuited to real-time computing at the scale required. Whereas the former required large-scale consolidation of old state data before writing in new data, Blink stores only increment data at checkpoints, saving previous checkpoint data history.
Blink thus eliminates the unnecessary consolidation of all old state thereby allowing each checkpoint to accomplish in a very short time. This helps to reduce the severe data delays due to backtracking calculations during failover, removing their source entirely.
Asynchronous IO
Ordinarily, data needs to be placed into external storage to be retrieved by the network IO while in calculation. This generally uses a Sync-IO method which requires delivery of previous data sets before new requests can be made, wasting CPU resources as CPU will be in idle mode before the fetched data return.
To increase efficiency in the CPU bit computation, Blink includes a newly designed Async-IO data reading structure that allows an asynchronous, multi-thread data retrieval. The result is that the system no longer needs to wait for returning data to make subsequent requests, managing returning data by way of callback. Where the user requires an isotone, Blink will buffer earlier incoming data and wait for the compilation of all subsequent data, only then processing these in batch.
Async-IO can increase the current rate of computation by 10-100 fold, tremendously improving CPU utilization and computing function.
It is also worth noting that all the above-mentioned Blink Runtime optimization, including optimized cluster deployment, incremental checkpoint, and asynchronous IO, has been dedicated to Apache Flink. Due to these contributions, two developers from Alibaba’s real-time data infrastructure team were recognized and acknowledged as Apache Flink committers.
Flink SQL: Core features
Why SQL?
SQL offers numerous advantages in real-time computing. Firstly, it is a generic descriptive language enabling users to easily describe their desired job requests. On top of this it offers a better optimization structure, reducing disruptions to user experience so that users need only focus on the design of operation logic, rather than more complex status management and function optimization tasks, greatly reducing entry barriers.
SQL is easy to understand, accommodating adoption from users across diverse industries, and posing little requirement for elaborate coding and programing knowledge. From product designers to developers, most users will be able to master SQL fairly quickly.
The SQL API is also very stable during structural upgrades, not requiring users to amend their Jobs to continue using it during computation engine replacement. When necessary, SQL can unify batch computing and stream computing within the same query.
The Alibaba real-time data infrastructure team is the biggest contributor to Apache Flink SQL apart from DataArtisans, the company founded by the original creators of Apache Flink. The developers on this team have helped define the semantics of Flink SQL and developed many important features.
Stream computing versus batch computing
To define the SQL semantics for stream computing, it is vital to understand the difference between stream and batch computing. The data handled by stream computing is indefinite, while batch computing is limited to a certain fixed data. Three further distinctions can help define their respective functions.
First, stream computing perpetually produces results without terminating processes, while batch computing normally shuts down immediately after reverting a final result. Taking the Double 11 Singles’ Day festival as an example, using batch computing to calculate the day’s total transaction volume would require calculating the total sum of every single buyer’s expenditure after all transactions had closed at the end of day. By contrast, stream computing would trace transaction values in real time and conduct instantaneous computations, continuously updating the latest results. The advantages of the latter are thus obvious.
Stream computing also requires checkpoint assessment and a retainment of status, and can continue to run at high speeds during failover. By contrast, batch computing input data is sustained for a period and then stored, so there is no cause for retaining status.
Lastly, the input data of stream computing is updated constantly, and can thus accommodate situations where a buyer’s sum expenditure changes continuously over time. Batch computing would by contrast base its calculations on the total sum expenditure at end of day. Thus stream computing is a pre-estimation of a final result requiring a retraction of computations done in advance to make further amendments, while batch computing does not require this retraction process.
The differences described above do not influence users’ task logic, which means their variations will not be reflected on SQL. Rather, the user is able to interact with results and save states using a Query Configuration featuring Latency SLA, and State Retention/TTL components.
Flink SQL on Alibaba StreamCompute platform

The technical specifications of Flink SQL on Alibaba StreamCompute platform encompass a vast range of breakthrough improvements for stream SQL data computing.
Among these, the updated SQL features a dynamic table[2] capable of updating with incoming data while preserving the unity of data, enabling continuous stream inquiry. It further enables stream-stream join, lookup join, window aggregation, “retraction” functionality to ensure the stream computing results are eventually consistent with batch computing, and lots of query optimizations.
All of these features and optimizations are now available from the Alibaba StreamCompute platform, while some of them have been contributed into Apache Flink. Due to these contributions, three developers from Alibaba’s real-time data infrastructure team were recognized and acknowledged as Apache Flink committers.
Alibaba real-time computing applications
To date, Alibaba has successfully developed two standalone platforms by applying the stream computing SQL model summarized above.
StreamCompute
 Screenshot of AliCloud development platform StreamCompute
Screenshot of AliCloud development platform StreamCompute
AliCloud’s StreamCompute integrates all demands for real-time computation, from development, debugging, and online deployment to operation and maintenance, vastly increasing development efficiency. This platform played a prominent role in the 2017 Double 11 Singles’ Day Global Shopping Festival, publishing a majority of Ali group companies’ real-time computations.
Real-time machine learning platform
Alibaba has also developed a real-time machine learning platform, designed to enhance the efficiency and effectiveness of machine learning tasks.
Looking ahead
Alibaba will be opening the AliCloud Stream Computing platform to external enterprises beginning from April 2018, and is continuing to pursue the development of enhanced real-time computing in the meantime. The real-time machine-learning platform is currently only available for internal developers but opening it up to external enterprises will be considered in the near future.
For more information about Blink, Flink, and real-time computing at Alibaba please follow the links below.
[1] Xiaowei Jiang, A Year of Blink at Alibaba: Apache Flink in Large Scale Production, http://www.dataversity.net/year-blink-alibaba/, May 19, 2017
[2] Fabian Hueske, Shaoxuan Wang, Xiaowei Jiang, Continuous Queries on Dynamic Tables, http://flink.apache.org/news/2017/04/04/dynamic-tables.html, April 4, 2017
[3] Xiaowei Jiang, Bring Flink to Large Scale Production, https://www.youtube.com/watch?v=nuu_Zat6yus, Flink Forward at Berlin, Sep. 13, 2017
[4] Shaoxuan Wang, Large Scale Stream Processing with Blink SQL at Alibaba, https://www.youtube.com/watch?v=-Q9VG5QwLzY, Flink Forward at Berlin, Sep. 12, 2017
[5] Feng Wang, Zhijiang Wang, Runtime Improvements in Blink for Large Scale Streaming at Alibaba, https://www.youtube.com/watch?v=-19fvqcZstI, Flink Forward at San Francisco, Apr. 11, 2017
[6] Xiaowei Jiang, Shaoxuan Wang, Blink's Improvements to Flink SQL And TableAPI, https://www.youtube.com/watch?v=WrO48xCr4pw, Flink Forward at San Francisco, Apr. 11, 2017
First hand, detailed, and in-depth information about Alibaba’s latest technology → Search “Alibaba Tech” on Facebook
