- Build a Distributed Code Hosting Platform that Supports Millions of Users
Best practice from Alibaba tech team
In the past year, Alibaba’s GitLab request volume increased four times, its number of projects increased by 130%, and its number of users increased by 56%. However, despite such rapid growth, the accuracy of system calls has actually increased from 99.5% to over 99.99%.

This success comes down to the innovative design of Alibaba;s GitLab architecture which has been developed based on GitLab Community Edition v8.3 and currently supports tens of thousands of members in R&D teams across the company.
The Challenge
To date, hundreds of thousands of projects have been created with tens of millions of requests made per day, with storage running to the terabyte level. These numbers greatly exceed the upper capacity limit promised by GitLab’s standalone edition and are increasing fast.
Faced with this challenge, the logical approach is to simply expand the capacity. However, unfortunately, GitLab Community Edition is designed based on a "standalone" mode, making it hard to expand the capacity because of bottlenecks with the storage and standalone load.
This is because GitLab's design fails to comply with the fourth factor of the Twelve-Factor App embraced by Heroku, to treat backing services as attached resources. As such, Git warehouse data is stored on local servers with the three major components relied on by GitLab (libgit2, git and grit) directly operating on the file systems.
So, what was the Alibaba Tech Team’s solution?
In early 2015, the standalone load of Alibaba's GitLab began to get seriously overwhelmed. At that point, the solution was to synchronize all the warehouse data on multiple servers and distribute the requests to reduce the load on individual servers. However, that method was just palliative, and didn’t really address the core issue.
Namely because data synchronization during system operations consumed resources and time, making it impossible to expand the servers unlimitedly, and because while it only temporarily alleviated the issue with standalone load, but did nothing to help solve the issue the standalone storage limits.
In mid-2015, the team officially launched its first retrofit attempt, with the idea to get rid of the dependency on local file systems and use shared network storage instead.
However, due to the limitations of local caching and other issues, the shared network storage solutions had obvious performance issues, and most of them were underlying changes based on C/C++ with extremely high transformation costs.
At that time, the Group's GitLab servers often saw 95%, or even higher, CPU utilization above the alert threshold value, and this load also led to a high percentage of erroneous requests. This posed serious challenges for both the stability of downstream applications and user experience.
Thus, in August 2016, a new round of transformation began. Since shared storage could not solve the problem, attention was turned to distributed or sliced storage.
The team noticed that that the characteristic name of a warehouse in GitLab was "namespace_path/repo_path" and this was contained in almost every request's URL or ID information.
This name then could be used as the basis for slicing, routing warehouses of different names to different servers and route requests related to the warehouses to the corresponding servers. Thus, services could be scaled horizontally. The image below illustrates the architecture of Alibaba's current GitLab in a single data center.
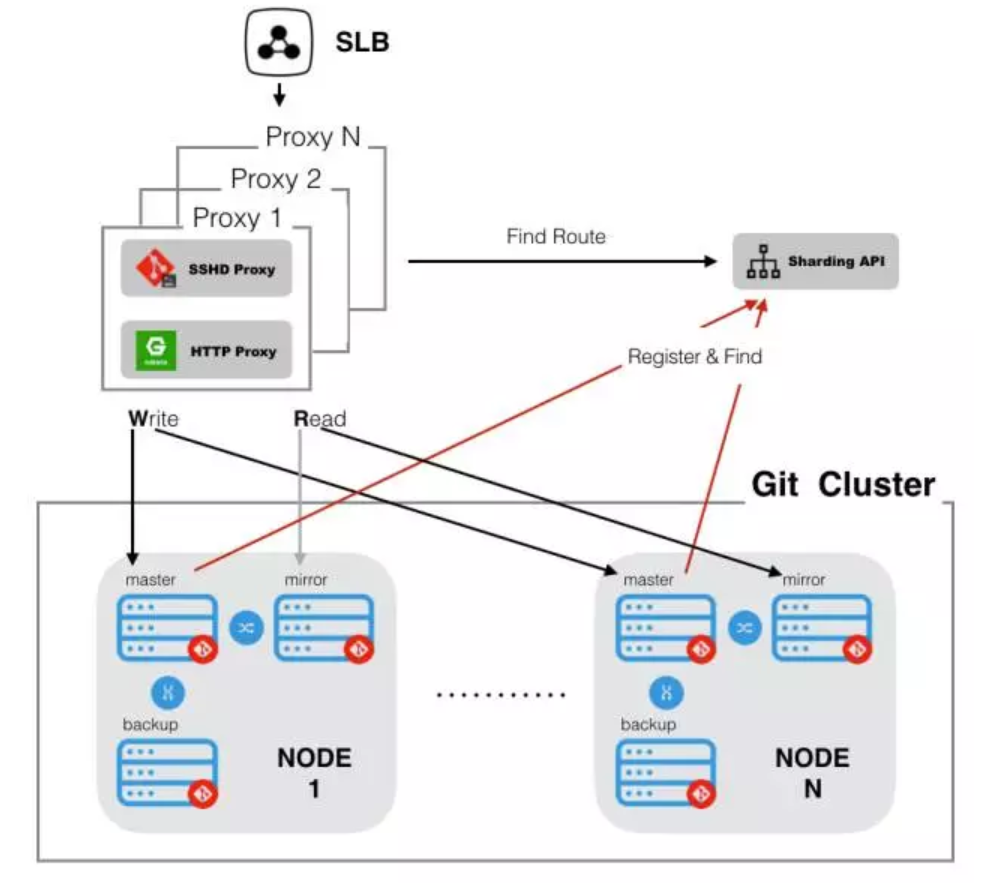
Components
- The Sharding-Proxy-Api is used to record the correspondence between the warehouse and the target server.
- The Proxy is responsible for unified processing of requests and accesses information through the Sharding-Proxy-Api, thus routing the requests to the correct target servers.
- The Git Cluster consists of multiple nodes with each node having three servers, namely the Master, Mirror and Backup:
- The Master is mainly responsible for processing the write (POST/PUT/DELETE) requests
- The Mirror is mainly responsible for processing the read (GET) requests
- The Backup serves as the hot backup server within the node.
Procedure
After Master processes the write requests, it syncs the update change simultaneously to Mirror and Backup/. This ensures the accuracy of the read requests and the data on the hot backup server (dual-master mode was not used because mutual overwriting might be caused by two-way synchronization, resulting in dirty data).
How to ensure correct slicing information
Developed based on the Martini architecture, Sharding-Proxy-Api receives notifications from GitLab in real time to dynamically update the warehouse information. This ensures the accuracy of the data in case of namespace or project additions, deletions or modifications, namespace_path changes, or warehouse transfers.
In such a scenario, one or more interactions with Sharding-Proxy-Api are being added per request. Initially, there were concerns about the impact of this on the performance however, due to the simpler logic and the excellent performance of Golang under high concurrency, the current response time of Sharding-Proxy-Api is within about 5ms.
How to ensure slicing rationality
In case of massive data, it is entirely possible to hash with the first letter of the namespace_path as the basis for slicing. However, due to the special nature of some names, there might appear hot libraries (i.e. some namespaces had very large storage or a great number of corresponding requests). To solve this, corresponding weights were allocated to the storage and the number of requests, and slicing was performed according to the weighted results. This balances the three nodes in terms of load and storage resource consumption.
How to deal with cross-slice requests
In addition to operations for a single namespace or project, GitLab also has operations for multiple namespaces and projects, including transferring projects, forking projects, and merging requests across projects. However, the system can’t guarantee that the namespace or project information required for those operations, would be stored on the same server.
To this end, the GitLab code for those scenarios was modified to get the information in the form of SSH or HTTP requests if a request fell on a server and needed information from a namespace or project on another server. In such scenarios, the team’s ultimate goal is to use RPC calls.
How to improve performance
1.Replacement of SSH protocol
Currently, Alibaba's GitLab provides both SSH protocol and HTTP protocol for users to perform fetch and push operations on the code library. Among them, the native SSH protocol is implemented based on the operating system's SSHD service, however, with a large number of concurrent GitLab SSH requests, some bugs may occur. This can result in it becoming slower for users to fetch and push code or to login to servers using the SSH protocol.
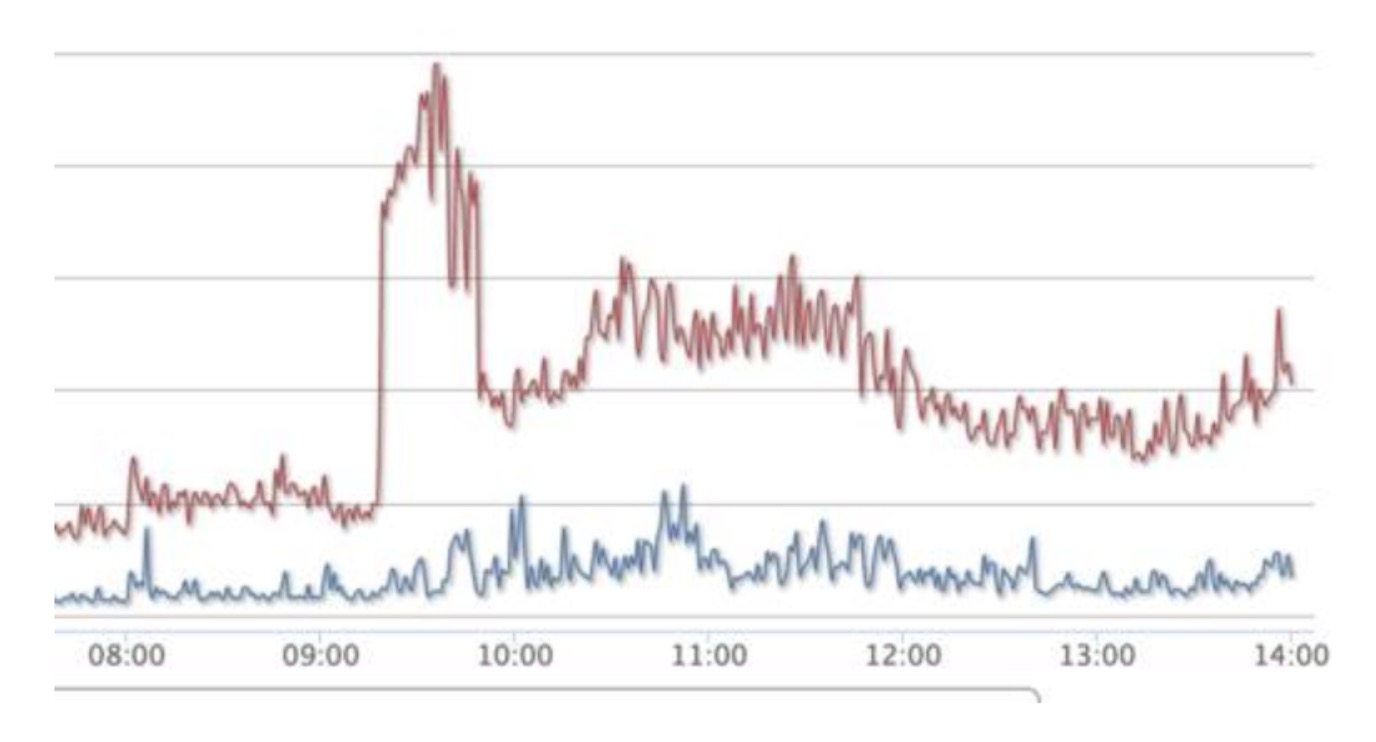
To solve this, the team employed Golang to rewrite the SSH protocol-based code data transmission capability and deployed it on Proxy servers and GitLab servers in different node groups. This means that the server load is significantly reduced, the bugs were eliminated, and, in the event of a problem with the SSH service, it is still possible to log in to the servers via SSH (using native SSH), and restarting SSHD service doesn't affect the servers themselves.
The figure below shows the CPU usage of the Proxy servers after using the new SSHD service:
 2.Optimization and rewriting of individual requests
2.Optimization and rewriting of individual requests
For large requests, such as interfaces for authentication and access to user information through SSH key, the text-to-MD5 or indexing methods are currently used to optimize the performance, and to conduct rewriting with Golang or Java.
How to ensure data security
1.One master and multiple backups
Each slice node of Alibaba's GitLab contains three servers, so three copies of data in corresponding warehouses are maintained. Even if unrecoverable disk faults happen to one or two servers, data retrieval is still available.
2.Cross-data center backup
In March 2017, a cross-data center switching drill was completed for Alibaba's GitLab to simulate the coping strategy in case of data center faults. Alert notifications were received within 1 minute after the occurrence of the fault, and the traffic was switched across data centers within 5 minutes of manual intervention (DNS switchover).
The Multi-data center disaster recovery architecture is shown below:

Ensuring quasi-real-time synchronization of warehouse data was the reason behind the data center switch, and the team’s aim was to make the disaster recovery data centers proactively initiate the data synchronization process according to actual needs. The basic steps are as follows:
- GitLab's system hook was used to issue messages in all scenarios where warehouse information was changed (including event types, time, data, etc.)
- Hook receiving service was deployed in the same data center. The data is formatted after the hook requests are received, and messages sent to related topics of Alibaba Cloud's Message Notify Service (MNS)
- Message consuming service was deployed in the disaster recovery data center which subscribes to related MNS topics to get the messages via the online data center in real time. After the messages are received, the RPC service (deployed on the GitLab node servers in the disaster recovery data center), is called to proactively initiate and realize the logic of data synchronization.
Hook receipt, message consumption, and RPC service on the GitLab node servers were all implemented using Golang. RPC service was based on grpc-go and used protobuf to serialize the data.
Following operations and drills, it was determined that the solution was feasible. With the cooperation of data validation and monitoring personnel, the disaster recovery data center could synchronize the data in the online data center in quasi-real time, and ensure 99.9% to 99.99% data consistency.
Cellular deployment
The cellular architecture evolved from the field of parallel computing. In the field of distributed service design, a cell is a self-contained installation that satisfies all the business operations of a shard. A shard, on the other hand, is a subset in the overall data set. If you use ending numbers to sort users, the users with the same number can be considered a shard. Cellization is the process of redesigning a service to fit the characteristics of cells.
For the Tech Team, this was taken into account right from the beginning. For example, in the cross-data center backup, when the message consuming applications need to call the Sharding-Proxy-Api to obtain the addresses of RPC services, the data can be made circulate within a closed-loop in one single data center. In this way, while meeting the requirements of cellization, in case of data center failure, data cut-off is avoided as much as possible during the consumption of the messages already in the queue.
This means, Alibaba's GitLab basically has the ability of cellular deployment embedded in the architecture. As a result, no matter whether it is subsequent cooperation with Alibaba Cloud to provide services externally, or new acquisition of overseas companies where separate services have to be built, things can go smoothly without problems.
Looking to the future
The success of the system is apparent in the increase in accuracy despite such large increases in volume, projects and users. Still, the Tech Team believe there is a number of improvements that can be made including a fully automatic publication and expansion mechanism to deal with the deployment of more servers.
In addition, only when the final replacement of the global RPC services is realized can the resources consumed by web services and by GitLab itself be separated, and the distributed transformation of Alibaba's GitLab considered complete.
Nonetheless, Alibaba's current GitLab architecture is still powerful enough to support millions of users, and will serve more cloud developers gradually through Alibaba Cloud's mission to create a collaborative R&D cloud-based ecosystem in the cloud.
(Original article by Li Bin)
. . .
Alibaba Tech
First hand, detailed, and in-depth information about Alibaba’s latest technology → Search “Alibaba Tech” on Facebook
