- Fight Peak Data Traffic On 11.11: The Secrets of Alibaba Stream Computing
When the clock turned midnight on 11.11 with tens of millions of shoppers rushing online, Alibaba’s stream computing didn’t panic at all.

Alibaba’s Hangzhou Campus during the 11.11 Global Shopping Festival
On November 11th, 2017, the global shopping festival known as Single’s Day, or 11/11, broke yet another record with 256,000 successful payments and 472 million real-time data events processed per second at its peak. With 100% more data volume compared to the previous year, stream computing played a vital role in meeting that challenge
When the clock turned midnight on 11/11, tens of millions of shoppers rushed online, searching for and buying the best deals around.
While everyone enjoyed the carnival at the frontend, data traffic was flowing into the backend at record rates.
256,000 successful payments and 472 million log events processed per second at the peak
The centralized data layer, the most important layer in stream processing, secures core tasks such as processing business data in real time, and set a record 180 million log events processed per second during peak hours on 11/11. Although we are talking about numerous transactions from numerous users in just one second, stream computing was designed specifically to meet these high-speed data processing requirements.
As the value of data decreases rapidly over time, data must be computed and processed as quickly as possible after it is generated, to maximize value created from the data and to give the best user experience.
|
Peak Data Volumes 2016 vs 2017 · 2016: 120,000 payments successfully made per second and 93 million log events processed per second at peak volume · 2017: 256,000 payments successfully made per second, 472 million log events processed per second at peak volume, with 180 million of those log events processed using the centralized data layer. |
A stable second-level latency was achieved even with doubling peak traffic (compared to the previous year). From the first second when millions of shoppers rushed onto the digital stores, placed orders, and made payments, to the aggregation result displayed on media screens via stream processing, a second-level latency was achieved. In the face of increasing traffic, stream processing is getting faster and more accurate. The secret weapon behind the successful handling of the peak traffic is the comprehensive upgrade of Alibaba's stream computing platform.
Application scenarios of stream computing
The Department of Data Technology and Products acts as Alibaba's centralized data platform, and the batch and streaming data it generates serves for multiple data application scenarios within the group. During the 2017 11/11 Shopping Festival (as with previous years), the real-time data for media displays, real-time business intelligence data for merchants, and various live studio products for executives and customer service representatives originate from the Big Data Business Unit of Alibaba.
Meanwhile, as the business continues to grow and develop, the daily stream data processing amount is currently at 40 million log events per second at its peak, and trillions of records with petabytes of data are processed per day.
Despite the massive amount streaming data, the team succeeded in achieving second-level data latency and high-precision zero-error computation accuracy. For example, in 2017, the first transaction record was recorded in just 3 seconds after being processed with stream computing.
Data link architecture in stream computing
After experiencing a flood of data traffic in recent years, the Alibaba stream computing team has gained extensive experience in engine selection, performance optimization, and the development of streaming computing platforms. As shown below, they have established a stable and efficient data pipeline architecture.

Business data comes from various sources. Incremental data is obtained in real time through two tools, DRC and the middleware's LogAgent, and synchronized to DataHub (a PubSub service).
Blink (Alibaba’s internal version of Apache Flink), the stream processing engine, processes the incremental data in real time through subscription. The detail layer is reflowed to DataHub after processing with ETL. All the business parties define the real-time data for multi-dimensional aggregation. The aggregated data is stored in distributed or relational databases (HBase, MySQL), and real-time data services are offered externally through centralized data layer service products (OneService).
For 2017, a lot of focus was put on computing engines, in particular optimization to improve computing capabilities and development efficiency.
Computing engine upgrade and optimization
In 2017, the Alibaba streaming computing team fully upgraded their stream computing architecture, migrated from Storm to Blink, and optimized the new technology architecture with more than twice the peak stream processing capability and more than five times processing capability on average.
Optimized state management
A huge number of states are generated during stream computation. They were formerly stored in HBase, but now they are stored in RocksDB, reducing network consumption by local storage and dramatically improving the performance to meet the requirements of fine-grained data computation. The number of keys can now reach hundreds of millions.
Optimize checkpoint (snapshot / checkpoint) and compaction (merge)
The states will get bigger and bigger over time, so if a full checkpoint is performed every time, the pressure on the network and disks would be extremely high. This means, in data computation scenarios, that optimizing the RocksDB configuration and using incremental checkpoints can significantly reduce network transmission and disk reads and writes.
Asynchronous sink
By making sink asynchronous, the CPU utilization can be maximized to significantly improve TPS.
Abstracted public components
In addition to the engine-level optimization, an aggregation component based on Blink was developed for the centralized data platform (currently, all stream tasks on the centralized data layer are implemented based on this component). This component provides commonly used functions in data computation and abstracts the topology and business logics into a JSON file. This way, development configurations can be carried out by controlling the parameters in the JSON file, making it much easier to develop, and shortening the development cycle. For example, the development workload was at 10 people per day, but with the componentization, the workload dropped to just 0.5 people per day, which is good for both the product managers and the developers. Also, the unified component improves task performance.
Eventually a stream computing development platform, Chitu, was created based on the these ideas and functions.
The platform generates streaming tasks in a simple "drag-and-drop" form without the need to write a single line of code. It also provides regular data computation components, and integrates various features such as metadata management and reporting system connectivity. The Chitu platform comes with these unique features:
1.Dimension merge
Many statistical tasks need to perform computing with day-level granularity and hour-level granularity. Previously, they were carried out separately through two tasks. However, now the aggregation component merges those tasks and shares the intermediate states, reducing network transmission by over 50%, simplifying the computation logic, and saving CPU consumption.
2.Streamlined storage
For the key values stored in RocksDB, an index-based encoding mechanism was designed to effectively reduce state storage by more than half. This optimization effectively reduces the pressure on network, CPU, and disks.
3.High-performance sorting
Sorting is a very common scenario in streaming tasks. The Top component uses the PriorityQueue (priority queue) in the memory and the new MapState (state management provided by Blink Framework) feature in Blink to dramatically reduce the times of serializations and improve performance by 10 times.
4.Batch transmission and write
When writing the final result tables to HBase and DataHub, if every single record processed is written to the remote sink, the throughput would be greatly limited. Through the time-trigger or record-trigger mechanisms (timer function), the components can perform batch transmission and batch write (mini-batch sink). This can be flexibly configured based on actual business latency requirements, increasing task throughput and lowering pressure on the service end.
Data protection
For high-priority applications (24/7 services), cross-data center disaster recovery capability is required, so when a link is faulty, another link can be switched to at the second level. As shown in the figure below, the link protection architecture on the entire real-time centralized data layer.
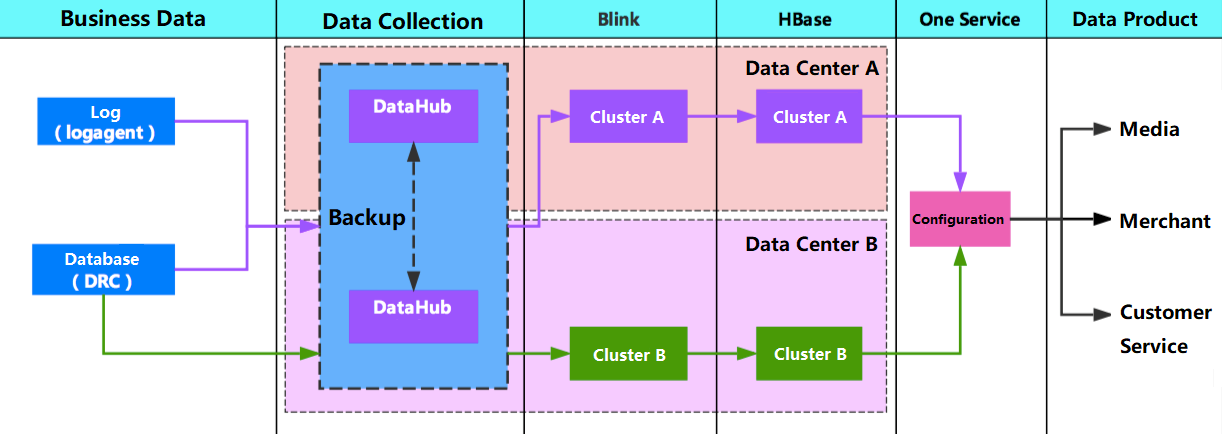
Real-time data pipeline during 11.11 Global Shopping Festival
From data collection, data synchronization, data computation, data storage to data servicing, the entire link is independent. Through the dynamic configuration in OneService, link switching can be achieved to ensure data service continuity.
Blink and xtool are the Alibaba stream computing team’s secret weapons for coping with the peak data traffic on 11/11. The aim is not only to innovate but also reuse and optimize those innovations for daily tasks.
With the ever-changing stream computing technology, Alibaba hopes to keep optimizing and upgrading their stream computing in a rich set of business scenarios:
1.Stream processing as a service
2.Unification of the semantic layer (for example, Apache Beam, Blink Table API and, Stream SQL are all popular projects)
3.Real-time intelligence: The popular deep learning may interact with stream computing in the future
4.Unification of streaming processing and batch processing: This is a big trend. Compared to the ubiquitous practice nowadays of one system for stream processing and one system for batch processing, unification is something major engines are working hard to achieve
(Original article by Chen Tongjie and Huang Xiaofeng)
. . .
Alibaba Tech
First hand, detailed, and in-depth information about Alibaba’s latest technology → Search “Alibaba Tech” on Facebook
